
Message Queue & Queue System - 아키텍처의 핵심
시스템 설계 공부를 시작했을 때 "메시지 큐? 그냥 백엔드 작업을 나중에 처리해주는 거 아냐?"라고 생각했던 적이 있다면, 당신은 좋은 출발선에 서 있다. 이제 그 개념을 실무에서 어떻게 사용하고, 왜 빅테크들이 이 구조를 선택 했는지를 알아볼 차례다.

"이메일 한 통 보내는데 왜 10초씩 걸리지?"
이런 경험이 있다면, 메시지 큐가 왜 중요한지 곧 실감하게 될 것이다.
Message Queue 란 무엇인가?
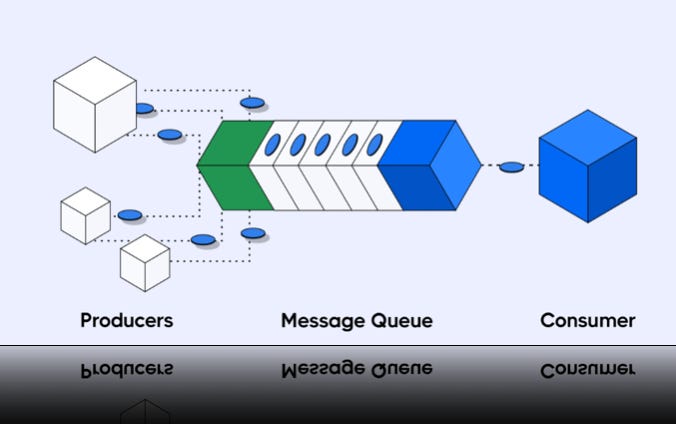
메시지 큐(Message Queue)는 시스템 구성 요소 간 데이터를 비동기적으로 전달할 수 있도록 해주는 중간 저장소다.
생산자(Producer) -메시지를 생성해서 큐에 넣는다.
소비자(Consumer) - 큐에서 메시지를 꺼내 작업을 수행한다.
이렇게 하면, 요청을 보내는 쪽과 받는 쪽이 동시에 동작하지 않아도 된다. 둘 사이의 결합도가 낮아지고, 트래픽이 몰려도 메시지를 일단 큐에 넣어두고 천천히 처리할 수 있다.
이 단순한 구조가 Google, Meta, Netflix, Amazon 같은 빅테크 시스템의 핵심이 되는 이유는 무엇일까?
메시지 큐와 Queue System이 어떻게 확장되는가?
Message Queue는 비동기 메시지를 저장/전달하는 버퍼다. Producer가 메시지를 큐에 넣고, Consumer가 이를 꺼내 처리한다. (Redis List 큐, Task Queue (RQ, Celery), Ticketmaster 시스템)
Queue System은 단순 메시지 큐를 넘어서, 전체 작업 흐름 관리와 대기열 제어, 작업 스케일링까지 포괄하는 넓은 개념이다. 예: Redis List 기반 작업 큐, DB 기반 작업 큐 등. (대기열 관리, 작업 흐름 제어, 분산 처리)
Netflix - 영상 트랜스코딩을 Kafka로 분리하라
사용자가 넷플릭스에 영상을 업로드한다고 상상해보자. 영상은 수 GB에 달하고, 이를 다양한 해상도로 변환해야 한다. 트랜스코딩은 CPU 자원을 많이 소모하는 작업이고, 실시간으로 처리하면 전체 시스템이 느려진다.
넷플릭스는 이 문제를 Kafka로 해결했다.
사용자가 영상을 업로드하면, 백엔드는 메타데이터 저장 후 "영상 트랜스코딩 요청" 이벤트를 Kafka에 발행한다.
트랜스코딩 워커(여러 개)는 Kafka로부터 메시지를 하나씩 받아 영상 변환을 수행한다.
변환이 끝나면 결과는 저장되고, 사용자는 최종 재생 가능한 상태를 확인한다.
이 구조 덕분에 넷플릭스는 트래픽이 몰리더라도 업로드 요청을 빠르게 수락하고, 무거운 작업은 백그라운드에서 병렬로 처리할 수 있다.
또한, Kafka의 로그 기반 구조 덕분에 처리 실패 시 재시도도 가능하다. 트랜스코딩 실패? 걱정 없다. Kafka는 메시지를 유지하고, 워커가 다시 꺼내어 처리할 수 있다.
Amazon - 주문 처리 시스템의 비밀 병기, SQS
아마존에서 상품을 주문하면, 수십 개의 시스템이 관여한다
재고 확인
결제 처리
배송 준비
이메일 알림
이 모든 작업이 하나의 API에서 순차적으로 이뤄진다면? 주문 하나에 10초씩 걸릴 수도 있다. 아마존은 이를 AWS SQS로 분산 처리한다.
사용자가 주문을 제출하면, 주문 정보는 DB에 저장되고 동시에 SQS 큐에 여러 메시지를 보낸다.
각각의 서비스(결제, 배송, 알림)는 자신의 큐를 구독하고 메시지를 하나씩 처리한다.
처리 결과는 따로 저장되거나, 후속 알림으로 이어진다.
덕분에
주문 접수는 2초 내 완료되고,
후속 작업은 트래픽과 무관하게 병렬 처리된다,
장애 발생 시 메시지를 큐에 유지해 복구 가능하다.
실제로 한 개발자가 경험한 사례
이메일 전송이 느려서 주문 완료까지 8초가 걸렸다. 이메일 발송을 큐로 분리하자 2초로 줄었다.
WhatsApp / Messenger - 메시지도 큐에 보관한다
메신저에서 친구에게 메시지를 보냈는데, 그 친구가 오프라인이라면?
Meta는 내부 메시지 큐 시스템(FOQS 등)을 통해 오프라인 사용자에게 도착한 메시지를 큐에 저장한다. 이후 친구가 온라인이 되면 메시지를 꺼내 전달한다.
또한 그룹채팅에서는 한 메시지를 여러 큐로 복사하여 전송한다. 이를 팬아웃(fan-out)이라고 하며, RabbitMQ와 같은 메시지 브로커가 이 기능을 잘 지원한다.
즉
채팅 메시지 → 큐에 저장
소비자(클라이언트 앱)가 접속 → 메시지를 읽어 UI에 표시
네트워크가 불안정하거나, 디바이스가 여러 개인 상황에서도 메시지가 손실되지 않는 이유다.
Gmail - 이메일도 바로 안 보낸다
이메일도 실은 "바로 보내지 않는다". Gmail의 SMTP 서버는 메일을 수신하면 큐에 저장한 뒤, 수신자 메일 서버로 전송을 시도한다.
만약 수신자 서버가 응답하지 않으면? → 일정 시간 후 재시도
몇 번 시도해도 실패하면? → 발신자에게 오류 이메일을 전송
대량 발송 시스템(뉴스레터 등)에서는 SendGrid나 SES와 같은 이메일 API를 사용할 때도 큐를 앞단에 둬서 API 호출 실패나 제한에 유연하게 대응한다.
이렇게 하면
사용자에게는 빠르게 "메일 발송 완료" 메시지를 보여주고,
실제 전송은 백그라운드에서 안전하게 처리된다.
기술 스택 비교 - Kafka, SQS, Pub/Sub, RabbitMQ
기술 특징 주요 사용처 Kafka 고속, 고내구성, 재처리 가능 Netflix, LinkedIn 로그 처리 SQS AWS 완전 관리형, 간단한 구성 Amazon 주문 처리 Pub/Sub GCP 기반, 서버리스에 적합 Gmail 알림, GCP 파이프라인 RabbitMQ 유연한 라우팅, 실시간 통신에 적합 WhatsApp, Slack 채팅 시스템
큐가 실무에서 해결하는 문제들
느린 작업 → 비동기로 분리
트래픽 폭주 → 큐로 완충
작업 실패 → 자동 재시도
시스템 간 결합도 → 낮아짐
일부 장애 → 전체 시스템 무력화 방지
큐는 확장의 핵심이다
시스템이 커질수록 처리해야 할 작업도 늘어난다. 이를 모두 한 API에 넣는 순간, 성능 저하와 장애는 시간문제다.
메시지 큐는 유연하고 안정적인 확장을 가능케 한다. 빅테크가 메시지 큐를 선택한 이유는 단순하다
"느려도 괜찮아, 큐에만 넣어줘. 나중에라도 반드시 처리할게."
당신의 서비스가 성장하고 있다면, 지금이 메시지 큐를 도입할 타이밍이다.
테슬라 옵티머스 로봇팀과의 인터뷰 사례
아래는 대규모 분석을 위한 메시지 큐 확장 방안에 대해 논의하려고 한다. 테슬라 옵티머스 로봇팀과 인터뷰 하면서 이 방안들에 대한 중요성을 깨달아서 정리를 해두었다.
옵티머스 로봇같은 경우에는 AR/VR 을 사용해서 Telemetry 시스템을 구축한 다음 학습을 진행하고 있는데 실시간으로 행동, 비전 데이터를 사용한 종합적인 상황 판단 학습을 만들 수 있도록 할 수 있는 방안으로 인터뷰에서 논의했었다.
OLAP DB - 대규모 분석을 위한 쿼리 최적화 데이터베이스
OLAP (Online Analytical Processing)은 수억 개 이상의 레코드에서 빠르게 통계 분석과 집계를 수행할 수 있도록 설계된 데이터베이스 시스템이다. 대표적으로 Amazon Redshift, ClickHouse, Snowflake 등이 있다.
요약하면, 분석 쿼리를 빠르게 처리하도록 설계된 데이터베이스입니다.
OLAP DB의 목적
빠른 집계 쿼리 처리 (GROUP BY, COUNT, SUM 등)
다차원 분석 (예: 유저 지역 + 시간 + 디바이스 조합 분석)
대시보드/BI 도구와의 연동
Redshift 예시 구성
Kafka/S3에서 실시간 또는 배치 데이터 수집
ETL/ELT 처리 후 Redshift로 적재
Pre-Aggregation된 데이터를 저장하여 쿼리 성능 향상
BI 도구/Tableau에서 직접 분석
Redshift 특징
Serverless 확장 기능으로 워크로드 예측 없이 사용량에 따라 자동 조정
S3 및 Kinesis 등 AWS 생태계와 밀접한 통합
데이터 웨어하우스로서 셀프 서비스 분석 환경에 적합
OLAP 쿼리 성능 최적화 전략
SORT KEY 선택 - 자주 조회하는 컬럼 기준으로 정렬 (예: user_id, timestamp)
DIST KEY 지정 - 조인이 자주 발생하는 컬럼 기준으로 데이터 분산 (예: session_id)
압축 인코딩 적용 - 컬럼 데이터 특성에 따라 RAW, ZSTD, LZO 등 선택
Pre-Aggregated Table 사용 - 매일 미리 계산된 결과를 저장해 실시간 쿼리 부하 감소
Spectrum/External Table - 과거 데이터는 S3에 두고, 자주 조회되는 최신 데이터만 Redshift 내부에 유지
사용 예시
광고 캠페인 리포팅
이커머스 판매 통계
고객 행동 분석 대시보드
메시지 큐 + OLAP DB 확장
시나리오
수십억 레코드를 OLAP 분석으로 빠르게 질의해야 할 때
구성
Kafka → S3 혹은 Direct Stream → Redshift로 데이터 적재
자주 조회되는 집계는 Pre-Aggregation된 상태로 저장
OLAP DB는 다중 사용자 동시 쿼리, 셀프서비스 분석 등 활용 가능
활용처
유저 행동 분석, 대시보드, 마케팅 효과 분석 등
Apache Flink - 실시간 데이터 스트리밍의 핵심
Apache Flink는 대규모 데이터 스트림을 실시간 또는 배치로 처리하는 분산 데이터 처리 프레임워크이다. 특히 Stream Processing(스트림 처리)에 최적화되어 있어 실시간 이벤트 기반 아키텍처에서 많이 사용된다.
Flink의 주요 특징
이벤트 기반 처리 - 메시지를 이벤트 단위로 처리하며, 순서 보장을 위해 타임스탬프 기반 윈도우를 설정할 수 있다.
실시간 스트리밍 - 데이터가 발생하는 즉시 처리 (예: 광고 클릭, IoT 센서 데이터)
Fault Tolerance - 장애가 발생해도 Checkpoint 기능으로 작업을 복원할 수 있다.
병렬 처리 - 클러스터 환경에서 다수의 TaskManager가 데이터를 병렬로 처리
Flink 구성 요소
JobManager - 작업 실행, 스케줄링, 클러스터 모니터링
TaskManager - 작업을 병렬로 실행하는 실제 노드
Windowing - 시간 단위로 데이터를 그룹화 (예: 1분 윈도우, 슬라이딩 윈도우 등)
Stream Processing - Flink의 핵심 기능. 지속적으로 흐르는 데이터를 실시간 변환 및 분석
실무 적용 사례
Ad Click Aggregator - Kafka로 수집한 광고 클릭 로그를 Flink가 실시간 집계 후 Redshift에 저장
Fraud Detection - 은행 트랜잭션을 실시간 분석해 이상 거래 감지
IoT Data Processing - 스마트 기기에서 수집된 센서 데이터를 실시간 분석 및 시각화
메시지 큐 + Apache Flink - 실시간 처리 파이프라인 확장
Flink란?
분산 스트리밍 프레임워크
실시간 데이터 분석/변환에 강함
체크포인트 기반 장애 복구 지원
활용 방식
Kafka로 들어온 실시간 데이터를 Flink가 이벤트 단위로 읽음
타임 윈도우 (ex. 1분) 기준으로 집계하거나, Fraud Detection 실행
적용 사례
광고 클릭 집계
이상 거래 감지 (은행, 핀테크)
IoT 센서 데이터 수집 및 분석 (스마트홈)
Kafka + Flink + OLAP - 현대 실시간 데이터 분석의 황금 트리오
Kafka - 대규모 이벤트 스트림 수집
Flink - 실시간 집계, 이상 탐지, 필터링 등 연산 수행
OLAP DB (Redshift/ClickHouse) - 최종 분석 결과 저장 및 시각화
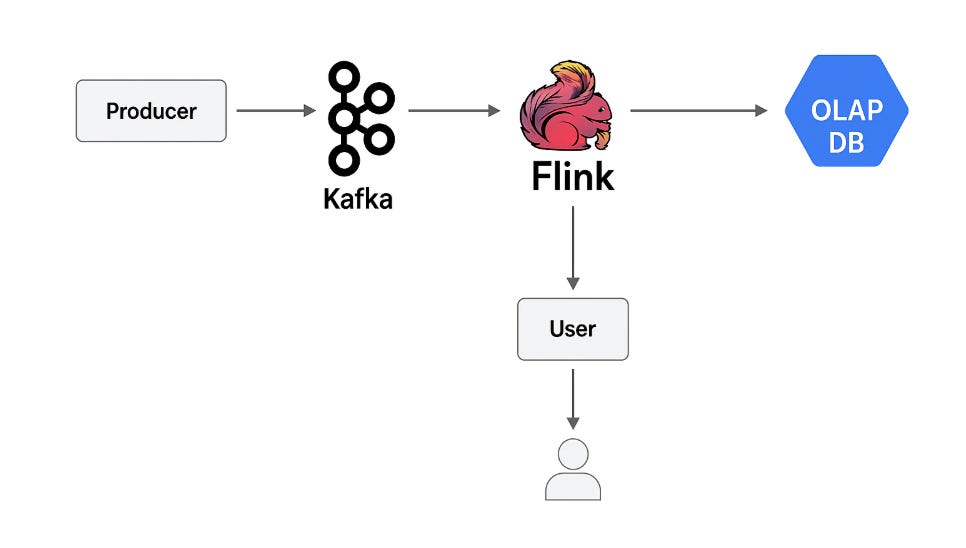
이 조합은 Meta, Uber, Netflix와 같은 빅테크뿐 아니라, 데이터 중심의 모든 기업에서 표준 아키텍처로 자리잡고 있다.
Apache Flink와 OLAP DB는 단순한 기술 도입을 넘어, 데이터 중심 아키텍처를 설계하는 핵심 구성 요소다. 메시지 큐를 중심에 두고 이들을 유기적으로 연계하면, 당신의 서비스도 실시간 대응력과 분석 인사이트를 동시에 가질 수 있다.
Message Queue는 단순한 백엔드 구성 요소를 넘어서, 대규모 실시간 시스템의 핵심 중간층으로 자리 잡고 있습니다. Kafka + Flink 조합은 실시간 처리의 대표이고, Queue System은 사용자 흐름 제어까지 포함하는 전반적인 아키텍처를 담당합니다.
실무에서는 메시지 큐의 종류 선택, OLAP 연동, 실시간 집계 파이프라인 설계까지 고려해 전체 흐름을 조율하는 설계 역량이 중요합니다. 이 글이 그 출발점이 되길 바랍니다.
실전 시나리오 #1 이메일 발송 지연 문제
문제 상황
한 스타트업의 웹 서비스에서 사용자가 회원가입을 하면 확인 이메일을 보내야 한다. 초반엔 문제가 없었지만, 사용자가 늘면서 이메일 발송 API가 느려지고, 회원가입 요청이 10초 이상 걸리는 일이 발생했다.
해결
메시지 큐 도입.
회원가입 로직은 사용자 정보 저장만 하고, 이메일 전송 요청 메시지를 큐에 넣는다.
별도 워커가 이 메시지를 받아 이메일을 발송한다.
이메일 전송 실패 시 워커가 재시도하며, 큐는 메시지를 보관한다.
AWS SQS 또는 RabbitMQ (작은 규모 서비스에 적합)
임팩트
회원가입 속도는 10초 → 1초 미만으로 감소
이메일 시스템이 일시적으로 죽어도 메시지는 유실되지 않음
재시도 로직이 표준화되어 예외 처리가 단순해짐
실전 시나리오 #2 쇼핑몰 주문 폭주 대응
문제 상황
특정 프로모션 시간(예: 오후 2시)마다 주문량이 100배 이상 폭주해 API가 다운되고 주문 실패율이 높아졌다.
해결
메시지 큐를 활용한 비동기 처리로 구조 개편
주문이 들어오면 DB에 저장하고, "결제 처리", "배송 준비", "이메일 발송" 등의 작업 요청을 각각 큐에 넣는다.
각 작업은 병렬적인 워커(혹은 서버리스 Lambda)가 큐를 구독해 자신의 작업을 처리
AWS SQS + SNS (Fan-out 구조), Kafka (대규모 트래픽)
임팩트
트래픽 급증 시에도 주문 API는 바로 응답 가능
작업이 느려도 큐가 완충지대 역할을 하며 전체 서비스 안정화
장애 대응 용이 (큐에 메시지가 남아 재시도 가능)
실전 시나리오 #3 영상 플랫폼 인코딩 파이프라인
문제 상황
사용자가 업로드한 영상을 다양한 해상도로 인코딩해야 하는데, 트랜스코딩 서버가 병목이 되고 업로드 지연이 발생함.
해결
영상 업로드 후 Kafka 큐에 인코딩 요청 메시지를 넣고, 여러 인코딩 워커가 이 큐를 구독하여 비동기 처리
Kafka (대용량 영상 시스템에 적합)
추가 처리
인코딩 실패 시 재시도 가능
완료된 인코딩은 또 다른 Kafka 토픽으로 후속 처리 (예: 썸네일 생성, 사용자 알림 등)
임팩트
업로드 후 사용자 인터페이스는 즉시 응답 가능
영상 변환은 병렬 + 비동기 처리
인코딩 실패율 감소, 운영 자동화
실전 시나리오 #4 실시간 채팅 시스템의 오프라인 메시지 처리
문제 상황
사용자가 오프라인일 때 받은 메시지가 유실되거나, 전송 실패가 발생함.
해결
메시지를 RabbitMQ와 같은 큐에 넣고,
클라이언트가 다시 온라인이 되면 메시지를 꺼내어 전송
RabbitMQ (다대다 라우팅에 유리), Meta FOQS
특징
멀티 디바이스 메시지 동기화
실패 메시지 자동 재전송
수신 확인(ACK), 재시도 처리 로직이 내장됨
임팩트
오프라인 사용자도 메시지 유실 없음
실시간성이 유지되면서도 안정적인 사용자 경험 보장
실전 시나리오 #5 - Ad Click Aggregator (Kafka + Flink)
문제
광고 클릭 데이터를 수집하고, 1분 단위로 집계한 뒤 OLAP DB에 저장해 분석하고 싶다.
구성
Kafka 각 사용자 클릭 이벤트를 메시지로 저장한다.
Flink Kafka에서 스트림을 읽고, 이벤트 기반으로 1분 단위 집계 처리
Redshift/ClickHouse 집계된 결과를 저장해 OLAP 분석
기술 포인트
Kafka는 데이터 순서를 보장하며 높은 처리량을 제공
Flink는 실시간 스트림 처리에 강하고, 장애 복구용 checkpoint 지원
OLAP DB는 빠른 분석 쿼리용으로 최적화됨 (Pre-Aggregation 권장)
실전 시나리오 #6 - 대기열 관리 시스템 (Queue System)
문제
수만 명의 사용자가 동시에 티켓을 예매하면 서버가 과부하된다. 대기열 시스템이 필요하다.
구성
사용자 요청 → Redis List에 push
Consumer 워커가 Redis에서 요청을 하나씩 꺼내 처리
결과는 DB에 저장하고 사용자에게 응답 반환
Queue System의 역할
대기열 정렬, 처리 순서 제어
스케일링이 필요한 작업을 병렬로 분배
대기 상태 사용자에게 피드백 제공 (ex. 예상 대기 시간)