
DBMS 완전 정복 시스템 구성부터 쿼리 최적화까지 [Final]

이번 글에서는 실제 대형 서비스들이 어떻게 쿼리를 최적화하고, 데이터를 분산하며, SQL과 NoSQL의 스키마를 현실적으로 설계해 왔는지를 집중적으로 분석합니다. 이 글을 통해 독자 여러분은 트위터(X), 인스타그램, 왓츠앱, 유튜브와 같은 시스템이 어떤 문제를 만나고, 어떤 전략으로 극복 했는지를 통해 "내가 설계해야 할 시스템"에 대한 감각을 구체화하게 될 것입니다. 목표는 단순한 암기가 아닌, 직관과 설계력을 키우는 것입니다.
1. 대규모 서비스를 위한 쿼리 최적화 전략 - 각 서비스의 핵심은?
X.com - 타임라인을 위한 시간 기반 인덱싱과 fan-out 전략
X의 타임라인은 전형적인 읽기 집중(read-heavy) 시스템입니다. 가장 큰 특징은 게시물 ID 자체에 시간 정보를 포함한 Snowflake ID 구조를 사용한다는 점입니다. 이를 통해 DB 인덱스를 따로 만들지 않고도, ID 정렬만으로 최신 게시물을 빠르게 조회할 수 있습니다.
또한 X는 fan-out on write 전략을 사용합니다. 새 게시물이 발생하면 팔로워 수만큼 Redis 리스트에 해당 게시물 ID를 미리 삽입해둡니다. 그 결과 사용자가 홈 타임라인을 열 때는 복잡한 조인 없이 본인의 Redis 리스트만 읽으면 됩니다. 쓰기 비용이 늘어나지만, 조회 시점의 비용은 극도로 낮춰 300K QPS를 처리할 수 있게 했습니다.
인스타그램 Instagram - ID 인코딩과 캐시 중심의 읽기 최적화
인스타그램은 Snowflake 유사 구조의 ID를 사용하여 시간순 정렬이 가능한 구조를 채택합니다. 피드 로딩 속도 향상을 위해 PostgreSQL과 Redis를 병행 사용하며, 자주 접근되는 피드, 활동 정보, 팔로우 피드 등을 Redis에 캐싱합니다. 이때의 전략은 명확합니다. "실시간성이 필요한 데이터만 캐시, 나머지는 비동기화". 이를 통해 실제로는 DB의 부하를 Redis가 거의 대부분 흡수합니다.
또한, 인기 콘텐츠나 해시태그 검색은 실시간 스트리밍 로그 분석을 통해 집계하며, 검색은 Elasticsearch를 통해 별도의 인덱스로 처리합니다. DB의 인덱스보다는 검색 특화 시스템으로의 분산 처리가 핵심입니다.
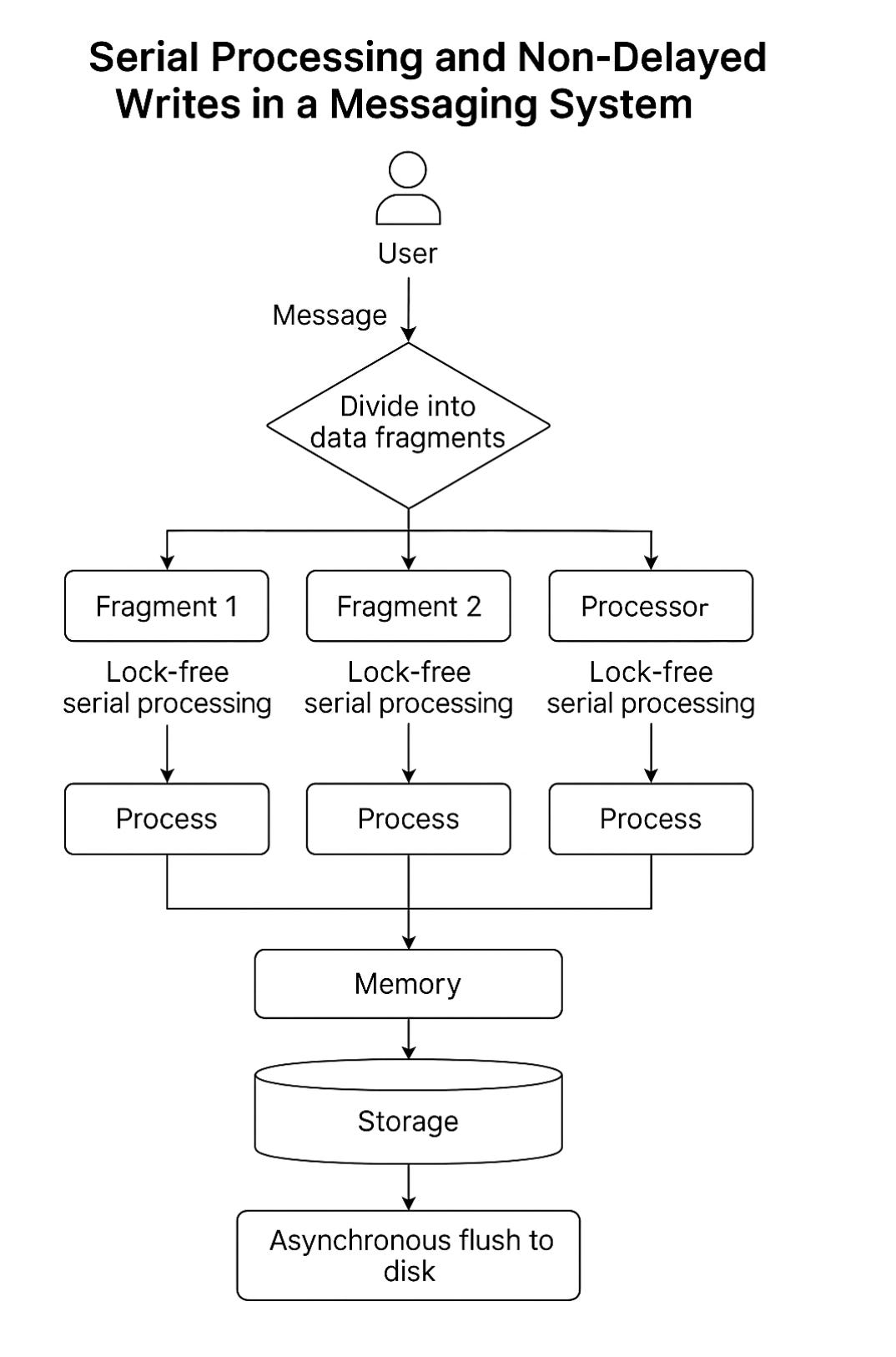
왓츠앱 - 메시징 시스템에서의 직렬 처리와 지연 없는 쓰기
왓츠앱은 실시간성과 쓰기 안정성이 중요합니다. 핵심 전략은 하나의 사용자 범위를 하나의 프로세스가 담당하도록 데이터 프래그먼트를 나누고, 각 프래그먼트에 대해 락 없는 직렬 처리를 한다는 점입니다. 덕분에 메시지 충돌이나 경합 없이 고성능 실시간 처리가 가능합니다.
왓츠앱 메시지 처리 흐름에서의 단계
메시지 수신
사용자가 메시지를 보냄
사용자 ID → 프래그먼트 매핑
해시값 등을 기반으로 어떤 프래그먼트/프로세스가 담당할지 결정
프래그먼트 프로세스가 요청을 직렬 처리
해당 범위의 메시지를 한 프로세스가 순서대로 처리 (lock-free queue)
예: 메시지 큐에 push
메모리에 우선 저장 (In-memory write buffer)
메시지는 DB가 아닌 메모리에 우선 저장됨 (예: ETS, RAM queue 등)
사용자에겐 이 시점에 이미 메시지 전송 완료처럼 응답이 감
비동기 flush - '지속성 보장(Persistence)'을 위한 단계
메모리에 쌓인 메시지들이 일정 조건(시간/버퍼 크기)에 도달하면
배치(batch)로 디스크에 비동기 저장됨이 작업은 사용자 응답 흐름과 별도로, 백그라운드에서 수행됨
즉, 왓츠앱에서는 수천만 명의 사용자가 실시간으로 메시지를 주고받기 때문에, 한 데이터베이스에 모두 몰리면 락(동시 접근 충돌)이 자주 발생하고 성능이 떨어질 수 있습니다. 이를 피하기 위해 왓츠앱은 전체 데이터를 쪼개어 '프래그먼트(fragment)'라는 단위로 나눕니다.
예를 들어, 사용자 ID의 해시값을 기준으로 1번 프래그먼트에는 1-999번을 할당하는 식입니다. 그리고 각 프래그먼트는 한 개의 프로세스(즉, 하나의 일꾼)가 전담합니다. 그러면 이 프로세스는 자신의 범위에 들어온 사용자 메시지 요청을 하나씩 순서대로 처리하게 되고, 동시에 여러 프로세스가 같은 데이터를 두고 싸울 일이 없으므로 락이 필요 없습니다.
그래서 쉽게 말하면, 한 줄에 1명씩 줄을 서서 입장하는 놀이공원처럼, 데이터도 줄을 세워서 한 프로세스가 순서대로 받아주는 구조인 셈입니다. 여기에 더해, 메시지를 디스크에 바로 쓰지 않고 먼저 메모리에 저장한 뒤, 나중에 천천히 저장하기 때문에, 디스크가 느려도 사용자에게는 빠르게 응답할 수 있습니다.
이 방식 덕분에 왓츠앱은 락 없이 하루 수백억 건의 메시지를 안정적으로 처리할 수 있습니다. 메시지는 메모리에 먼저 기록되고, 이후 디스크에 비동기 flush 되므로, 디스크 지연이 전송 지연으로 이어지지 않습니다. 실시간성, 쓰기 안정성, 락리스 처리라는 관점에서 왓츠앱은 매우 뛰어난 설계를 보여줍니다.
사용자 체감에는 영향을 주지 않음 → 성능 향상
메시지가 실시간으로 전송되지만, 디스크 쓰기는 늦게 일어나도 무방
실패 대비하여 replica에 이중 기록하거나 flush 실패 시 재시도 메커니즘 포함 가능
유튜브 - 조회수 처리와 Vitess를 통한 수평 확장
유튜브는 조회수 처리에서 Sharded Counter를 사용합니다. 단일 카운터를 동시에 업데이트할 경우 병목이 생기기 때문에, 여러 개의 샤드 카운터를 생성해 분산 업데이트하고, 조회 시 이를 합산합니다.
또한, 유튜브는 MySQL을 수천 개로 수평 확장하며, 이를 Vitess라는 미들웨어 프레임워크로 관리합니다. Vitess는 쿼리를 자동으로 재구성하고 적절한 샤드로 라우팅(Routing)해주며, 읽기 부하 분산을 위해 캐시까지 제공합니다. 이는 관계형 데이터베이스의 장점을 살리면서도 NoSQL처럼 분산 가능한 구조를 만듭니다.
2. 파티셔닝 전략 - 해시, 범위, 지역 기반의 선택과 설계
범위 기반 파티셔닝
X 에서 시간 범위별로 게시물을 분리할 때 사용되며, 최근 7일은 실시간 인덱스, 그 이후는 아카이브 인덱스로 분리하는 식입니다.
해시 기반 파티셔닝
인스타그램의 사용자 ID % N 방식처럼 데이터 균등 분산에 탁월합니다. 데이터 크기나 트래픽이 예측 불가능한 경우 적합합니다.
지역 기반 파티셔닝
인스타그램이 글로벌/로컬 데이터를 분리하거나, 유튜브가 CDN과 엣지 캐시를 이용해 동영상 접근을 빠르게 할 때 사용됩니다.
구글 엔지니어 모의 인터뷰 기출
파티셔닝 설계에서 중요한 점은 트래픽 집중을 방지하고, 확장성을 확보하며, 장애 격리에 유리하도록 분리 기준을 정하는 것입니다. 그렇기 때문에 설계하여야 하는 시스템에 따라 어떻게 파티셔닝(Partitioning) 을 하여야 하고 이에 따른 트레이드 오프를 함께 언급하여야 합니다.
SQL vs NoSQL 스키마 설계 전략 - 정규화와 비정규화의 경계에서
SQL(정규화)은 초기에 일관성과 관계 명확성, 업데이트 편의성을 위해 유리합니다. 인스타그램은 PostgreSQL 기반의 정규화된 스키마를 통해 데이터 정합성을 유지했습니다.
NoSQL(비정규화)은 읽기 성능을 위해 데이터를 중복 저장합니다. X의 타임라인은 한 게시물이 발생하면 팔로워 수만큼 타임라인 DB에 insert하는 방식으로 데이터를 미리 중복 저장합니다.
이 선택은 단순히 기술의 차이가 아니라 "주요 쿼리 패턴에 데이터를 어떻게 맞출 것인가"의 문제입니다. 읽기 최적화가 중요하다면 비정규화, 정합성이 중요하다면 정규화. 핵심은 쿼리 설계와 워크로드 분석에 있습니다.
짚고 넘어가는 빠르게 설계하는 시스템 디자인의 사고법
요구사항 분석
읽기/쓰기 중심, 일관성/가용성 우선 순위, 트래픽 피크 시간대 등을 파악합니다.
데이터 모델 설계
정규화 or 비정규화, SQL or NoSQL 선택, 그리고 어떤 인덱스를 만들 것인가 결정합니다.
파티셔닝 기준 선정
어떤 키로 샤딩할지, 샤드 개수는 어떻게 관리할지, 리샤딩은 가능한가?
인덱스와 캐시 설계
어떤 쿼리가 가장 많이 호출되는지 분석하고, 캐싱 전략과 TTL까지 설계합니다.
운영과 장애 대응 고려
장애 시 어떻게 복구할 것인지, 로깅/모니터링을 어떻게 할 것인지까지 염두에 둡니다.
인덱싱이란?
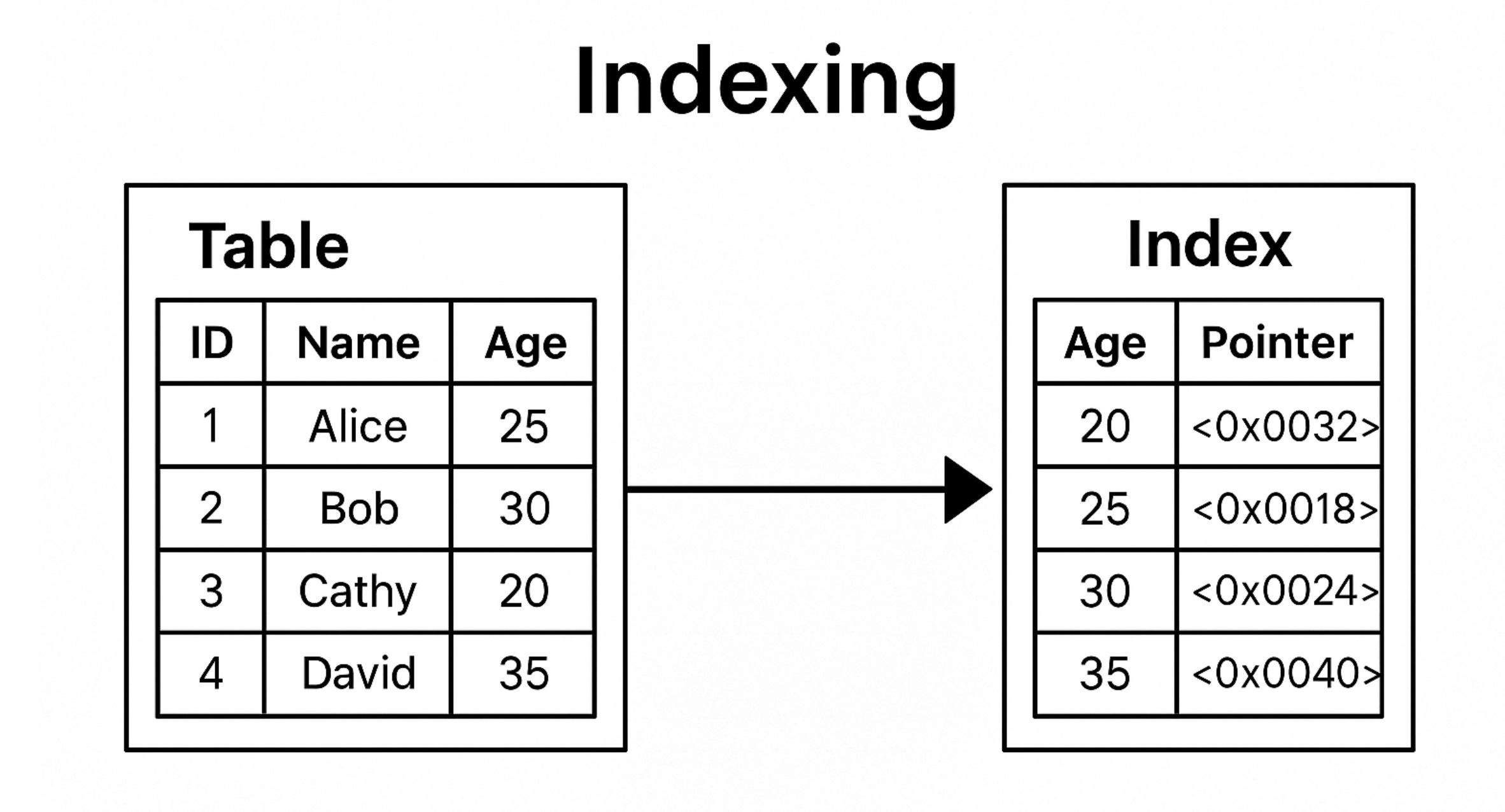
인덱스는 특정 컬럼의 값을 기반으로 정렬된 별도의 데이터 구조입니다. 이 구조는 해당 값이 저장된 실제 데이터의 위치를 가리키는 포인터를 포함하고 있어, 검색 시 전체 테이블을 스캔하는 대신 인덱스를 통해 빠르게 접근할 수 있습니다.
인덱싱의 장단점 (Trade-offs)
장점
빠른 조회 속도
인덱스를 사용하면 특정 조건의 데이터를 빠르게 찾을 수 있습니다.
정렬 및 그룹화 최적화
ORDER BY,GROUP BY절의 성능이 향상됩니다.
제약 조건 지원
PRIMARY KEY,UNIQUE제약 조건을 효과적으로 지원합니다.
단점
추가 저장 공간 필요
인덱스 자체가 추가적인 저장 공간을 차지합니다.
쓰기 성능 저하
데이터 삽입, 수정, 삭제 시 인덱스도 함께 업데이트되어야 하므로, 쓰기 작업의 성능이 저하될 수 있습니다.
복잡한 관리
불필요한 인덱스는 오히려 성능을 저하시킬 수 있어, 적절한 인덱스 설계와 관리가 필요합니다.
인덱싱이 유용한 시나리오
전자상거래 플랫폼
제품 검색
제품명을 기준으로 빠르게 검색할 수 있도록 인덱스를 생성합니다.
가격 필터링
가격 범위에 따른 필터링을 빠르게 수행하기 위해 가격 컬럼에 인덱스를 추가합니다.
소셜 미디어 서비스
사용자 피드
사용자 ID와 게시 시간에 대한 인덱스를 통해 최신 피드를 빠르게 로드합니다.
해시태그 검색
해시태그 컬럼에 인덱스를 생성하여 관련 게시물을 신속하게 검색합니다.
로그 분석 시스템
시간 기반 조회
로그의 타임스탬프에 인덱스를 추가하여 특정 시간대의 로그를 빠르게 조회합니다.
에러 코드 필터링
에러 코드에 대한 인덱스를 통해 특정 에러 로그를 신속하게 분석합니다.
파티셔닝이란?
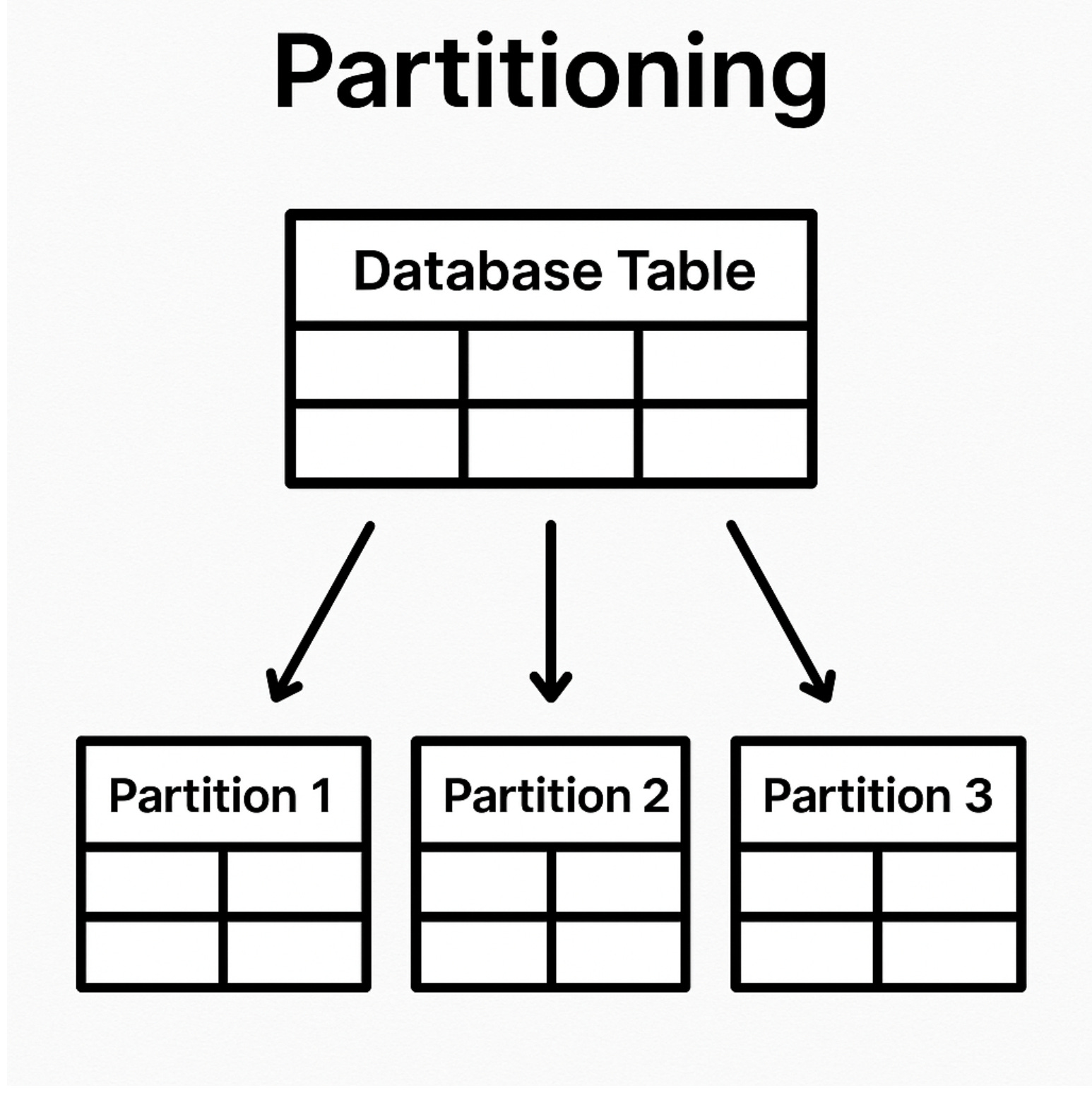
파티셔닝(Partitioning)은 하나의 테이블을 논리적으로 나누는 기술입니다.
즉, 하나의 거대한 테이블을 여러 개의 파티션(partition)으로 나누어 저장하되, 여전히 하나의 테이블처럼 쿼리할 수 있습니다.
물리적으로는 나눠지지만, 애플리케이션 레벨에서는 하나의 테이블처럼 사용 가능
파티셔닝의 종류
1. 범위 파티셔닝 (Range Partitioning)
예시
created_at날짜 기준으로 월별 파티션 나누기
장점
시간순 쿼리 최적화
단점
특정 파티션에 쏠림 발생 가능
PARTITION BY RANGE (created_at)
PARTITION p202401 VALUES LESS THAN ('2024-02-01'),
PARTITION p202402 VALUES LESS THAN ('2024-03-01');리스트 파티셔닝 (List Partitioning)
예시
지역 코드(서울, 부산, 대전) 기준 분리
장점
명확한 범주별 분리
단점
범주가 많아질수록 관리 복잡
해시 파티셔닝 (Hash Partitioning)
예시
user_id % 4로 4개 파티션에 균등 분산
장점
데이터 균등 분포에 유리
단점
특정 값 검색은 어렵고 full scan될 수 있음
복합 파티셔닝 (Composite Partitioning)
예시
시간별 + 해시 방식
장점
다차원 분산 가능 (예시: 날짜 + 사용자)
Trade-offs (장단점)
장점
조회 성능 향상 (쿼리 분할 실행)
파티션 단위 백업 및 삭제 가능
특정 쿼리 범위만 스캔하여 I/O 절감
장애 격리 및 유지보수 유리
단점
삽입/갱신 시 파티션 계산 비용 발생
너무 많은 파티션은 관리 오버헤드 유발
파티션 키 설계 실패 시 효과 미비
인덱스와 파티션의 관계 복잡
어떤 시스템에 사용되는가?
1. 로그 분석 시스템
파티셔닝 키
created_at (시간 기준)
사용 이유
최근 일주일만 자주 조회하고, 나머지는 cold storage로 관리
예: Splunk, ELK stack 기반 서비스
2. 전문 쇼핑몰(쿠팡, Amazon)
파티셔닝 키
카테고리 or 지역 or 재고 창고
사용 이유
정렬과 필터링이 빠르고, 판매자별 통계도 손쉽게 집계
3. 병원 전자의무기록(EMR) 시스템
파티셔닝 키
환자 ID or 방문일
사용 이유
환자별 데이터가 방대하므로 파티션으로 효율적 접근
MySQL - 범위 파티셔닝을 활용한 로그 테이블
요구사항
하루에 1천만 건 이상의 로그 기록
최근 30일 내 로그는 자주 조회됨
이후 데이터는 저장만 하고 거의 접근 없음
해결 방법
created_at기준으로 범위 파티셔닝 적용파티션 별로 TTL 정책 설정 → 주기적 drop
조회 성능 5배 향상, 스토리지 40% 절감
CREATE TABLE logs (
id BIGINT,
level VARCHAR(10),
message TEXT,
created_at DATETIME
)
PARTITION BY RANGE (TO_DAYS(created_at)) (
PARTITION p20240501 VALUES LESS THAN (TO_DAYS('2024-05-02')),
PARTITION p20240502 VALUES LESS THAN (TO_DAYS('2024-05-03')),
...
);
파티셔닝은 성능을 위한 전략이지, 데이터 구조의 목적이 아닙니다.
반드시 자주 조회되는 패턴을 분석한 후 설계하세요.
파티션별 인덱싱도 고려하세요 (파티션 프루닝 + 인덱스 조합 최적화)
MySQL, PostgreSQL, Oracle, ClickHouse, BigQuery 등 다양한 DB에서 파티셔닝 기능을 지원합니다.
샤딩(Sharding)이란?
샤딩은 데이터베이스의 데이터를 물리적으로 분할하여 여러 서버(DB 인스턴스)에 나누어 저장하는 기술입니다. 하나의 커다란 테이블을 여러 조각(샤드)으로 나누는 방식으로, 각 샤드는 독립적인 DB처럼 작동합니다.
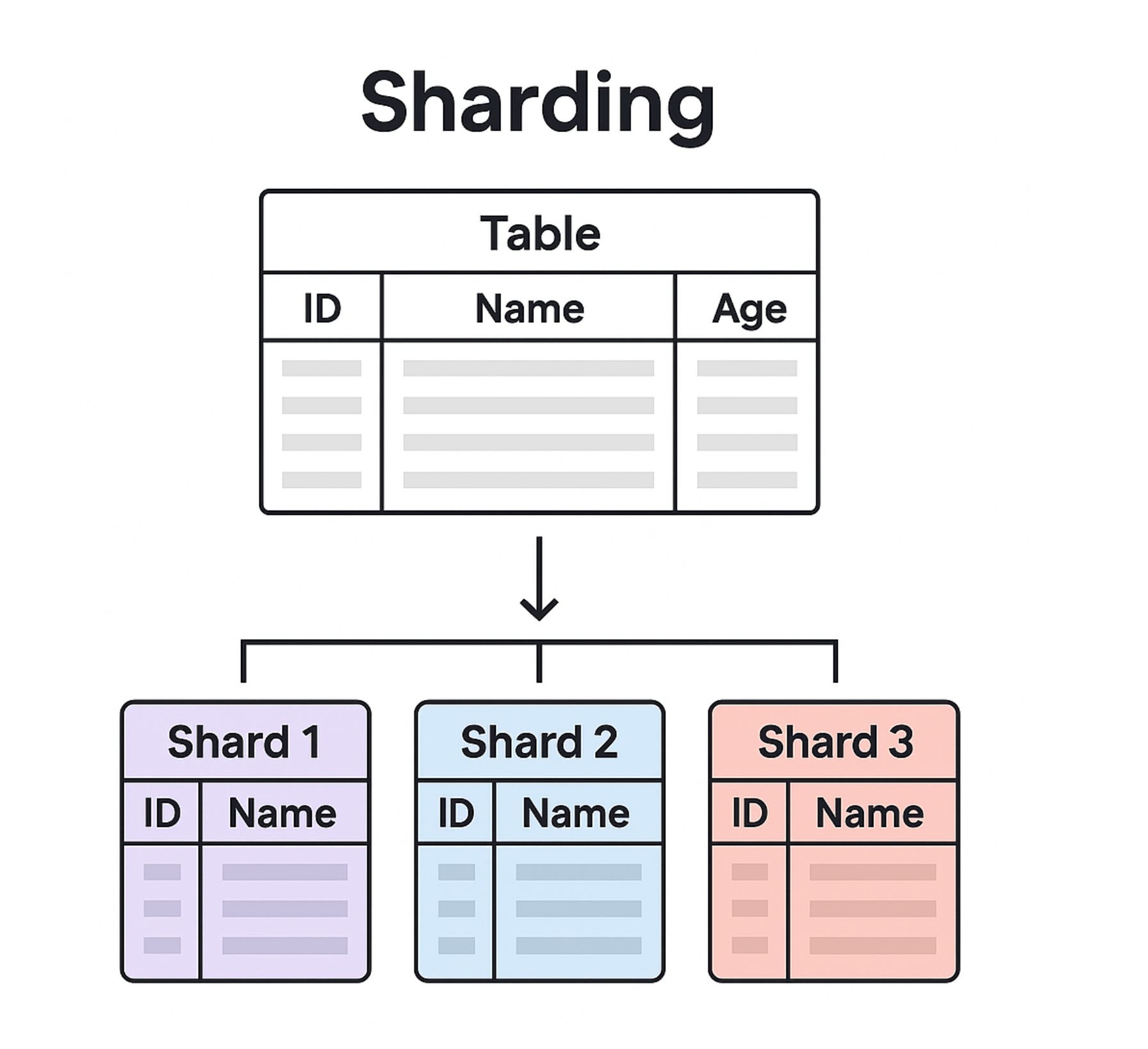
예를 들어 사용자 ID 기준으로 나눈다면
user_id 1~1,000,000 → shard 1
user_id 1,000,001~2,000,000 → shard 2
이런 식으로 나뉩니다.
성능 분산, 병목 해소, 수평 확장(horizontal scaling)
왜 샤딩이 필요한가?
단일 DB 인스턴스로는 다음과 같은 한계가 있습니다:
저장 용량 제한
트래픽 집중으로 인한 병목
특정 쿼리로 인한 락 경합
장애 발생 시 전체 시스템 중단
샤딩은 이러한 문제를 해결하며 데이터의 양이 수십억 건을 넘거나 QPS가 수천~수십만에 달하는 시스템에서 필수적인 구조입니다.
샤딩의 Trade-off
장점
수평 확장 가능
트래픽 분산
장애 격리 가능 (1샤드 장애 시 전체 다운 방지)
백업, 모니터링, 장애 복구를 샤드 단위로 분리 가능
단점
cross-shard JOIN 불가 또는 매우 복잡
샤딩 키 설계 실패 시 hot spot 발생
리샤딩이 어렵고 비용이 큼
운영 복잡도 증가 (N개의 DB 관리)
샤딩 적용 사례
1. SNS 플랫폼 (예: X, 인스타그램)
샤딩 기준
사용자 ID
이유
피드, 좋아요, 댓글 등 모든 데이터가 유저 기준으로 쏠림
샤딩 전략
User ID % N 방식 또는 consistent hashing
2. 금융 서비스 (예: Toss, 카카오뱅크)
샤딩 기준
계좌번호 / 고객 ID
이유
고객별로 독립된 거래기록이 많고, 보안상 격리 필요
샤딩 전략
Region + 계좌번호 prefix 기반
4. 전자상거래 (예: 쿠팡, Shopify)
샤딩 기준
판매자 ID / 주문 ID
이유
판매자 단위로 대규모 SKU/주문 관리
샤딩 전략
판매자 ID hash 기반, 인기 판매자 분리 샤딩
파티셔닝, 샤딩, 리샤딩을 함께 설계해보기
이 글은 시스템 아키텍처 설계 실전 감각을 키우는 시리즈의 마지막 편으로, 대규모 시스템에서 파티셔닝(Partitioning), 샤딩(Sharding), 리샤딩(Resharding)이 실제로 어떻게 설계되고 구현되는지를 다룹니다. 단순히 개념을 나열하는 것이 아니라, 실제로 서비스 규모가 커졌을 때 설계자가 어떤 문제를 만나고, 어떤 의사결정을 내려야 하는지 그 흐름을 도식과 코드 중심으로 직관적으로 설명합니다.
파티셔닝과 샤딩의 차이, 그리고 실전 설계 흐름
파티셔닝(Partitioning)은 데이터를 논리적으로 분할하는 행위입니다.
예: 범위 파티셔닝, 해시 파티셔닝, 지역 기반 파티셔닝 등.
샤딩(Sharding)은 물리적인 서버/디비 인스턴스로 나누는 것까지 포함합니다.
설계 흐름 예시 (X의 사용자 타임라인 예)
하나의 DB로는 감당 불가 → 데이터 분산 필요
타임라인은 사용자 단위로 분리 가능 → 사용자 ID 기반 파티셔닝 적합
사용자 ID % N = 샤드 번호 방식 도입 (해시 샤딩)
트래픽 증가 시 N을 늘리거나 샤드 스플리팅 필요 → 리샤딩 고려
실제 샤딩 키 설계 전략
샤딩 키를 고를 때 고려할 것
균등한 데이터 분포를 보장하는가?
쿼리가 해당 샤드만 보게 유도할 수 있는가?
리샤딩 시 이 키 기준으로 이동이 쉬운가?
-- 예시: 해시 기반 사용자 샤딩
CREATE TABLE user_posts_00 (...);
CREATE TABLE user_posts_01 (...);
-- 사용자 ID % 2 == 0 → user_posts_00, 나머지 → user_posts_01샤딩 키 선택에 실패하면 쿼리가 모든 샤드를 순회하거나, 특정 샤드에 트래픽이 몰리는 현상(hotspot)이 발생합니다.
리샤딩(Resharding) 전략과 도식
리샤딩이 필요한 시점
트래픽이 특정 샤드에 몰림
샤드당 저장 용량 초과
비즈니스 로직이 변경되어 기존 파티셔닝 방식이 불리함
리샤딩 과정 도식
새로운 샤딩 키 또는 샤드 수 설계
온라인 데이터 이관 (기존 테이블 → 신규 테이블)
트래픽 분기 처리 (동시 쓰기 → double-write)
검증 완료 후 기존 샤드 폐기
이중 쓰기(double-write)와 점진적 리디렉션은 실무에서 자주 사용됩니다.
# 리샤딩을 위한 간단한 double-write 예시
if user_id % 2 == 0:
write(user_posts_00, post)
write(user_posts_000, post) # new shard
else:
write(user_posts_01, post)
write(user_posts_001, post)샤딩된 환경에서의 쿼리 최적화
샤딩은 쿼리 최적화를 어렵게 만들 수 있습니다. 가장 좋은 방법은 쿼리를 샤드 단위로 국한시키는 것입니다.
-- 예: 사용자 ID가 123인 경우
SELECT * FROM user_posts_000 WHERE user_id = 123;Vitess 같은 미들웨어를 사용하면 cross-shard 쿼리를 프록시 계층에서 분해해서 실행할 수 있지만, 가능하면 데이터 모델을 샤드 범위 내에서 해결하도록 설계하는 것이 이상적입니다.
실전 시스템 설계 미니 예제 (팔로우 시스템)
요구사항
한 사용자는 최대 1M명까지 팔로우 가능
팔로우 관계는 읽기/쓰기 모두 많음
팔로우 목록은 정렬되어 있어야 함
설계 전략
사용자 ID 기준 해시 샤딩
각 샤드에
followings테이블 존재정렬된 리스트를 위해 created_at 인덱스 포함
CREATE TABLE followings_00 (
user_id BIGINT,
followee_id BIGINT,
created_at DATETIME,
PRIMARY KEY (user_id, followee_id)
);
CREATE INDEX idx_created_at ON followings_00(created_at);샤딩 키가 user_id이므로, 내 팔로잉 목록은 항상 한 샤드에서 조회할 수 있습니다.
샤딩과 리샤딩은 단순히 스케일링을 위한 기법이 아니라, 데이터 설계와 쿼리 설계의 구조 자체를 바꾸는 큰 결정입니다. 이 글에서 다룬 코드와 도식을 통해, 여러분의 시스템 디자인이 한층 더 명확하고 예측 가능해지기를 바랍니다.
인스타그램, 유튜브, 구글 같은 대규모 분산 시스템에서 실제로 사용되는 쿼리 최적화 전략과, 그 배경이 되는 데이터베이스의 내부 동작 원리를 집중적으로 다룹니다.
왜 쿼리 최적화가 중요한가?
다음과 같은 쿼리는 특히 성능 병목이 자주 발생합니다.
JOIN
여러 테이블 간 조인을 통해 복잡한 관계를 추출할 때
Aggregation
COUNT, SUM, AVG 등 대규모 집계 쿼리
Sorting (ORDER BY)
정렬 쿼리, 특히 LIMIT과 함께 사용할 경우
Range Queries: BETWEEN, >=, <= 등의 조건 검색
쿼리 내부 동작 - MySQL/PostgreSQL의 쿼리 수행 흐름
Parser
쿼리를 구문 분석하여 AST(Abstract Syntax Tree) 생성
Planner/Optimizer
가능한 실행 계획(예: 인덱스를 사용할지, Full Table Scan할지)을 모두 생성
비용 기반 최적화(Cost-Based Optimizer)로 가장 효율적인 실행 계획을 선택
Executor
실제로 데이터를 읽고 조합해 결과를 반환
이 과정에서 가장 중요한 것은 어떤 인덱스를 사용할지, 그리고 정렬/필터링/조인 순서를 어떻게 배치할지입니다.
B-Tree 인덱스 - 어떻게 동작하고 왜 빠른가?
B-Tree는 대부분의 관계형 DB에서 사용하는 인덱스 구조로, 다음과 같은 특징이 있습니다.
정렬된 구조
검색 시 이진 탐색 가능
균형 트리
어느 노드에서든 루트까지의 거리가 일정하여 O(log n) 조회 성능
리프 노드 연결
범위 조회(BETWEEN)에도 유리
예를 들어 SELECT * FROM orders WHERE user_id = 123 같은 쿼리는, user_id 컬럼에 B-Tree 인덱스가 있다면 전체 테이블을 읽지 않고도 log(n) 시간에 결과를 반환할 수 있습니다.
하지만 주의할 점은?
복합 인덱스 (e.g.
(user_id, created_at))는 선행 컬럼 순서에 따라 인덱스가 활용됩니다. 순서를 반대로 하면 인덱스가 무시될 수 있습니다.
JOIN 쿼리 최적화 (Instagram 사례)
인스타그램에서 피드 로딩 시 다음과 같은 쿼리가 있을 수 있습니다
SELECT posts.*
FROM posts
JOIN follows ON posts.user_id = follows.followee_id
WHERE follows.follower_id = :user_id
ORDER BY posts.created_at DESC
LIMIT 20;문제점
follows테이블에서follower_id로 필터링 후,posts테이블과 JOIN,정렬 후 LIMIT
최적화 전략
follows(follower_id)인덱스 생성posts(user_id, created_at)복합 인덱스 생성Redis로 fan-out on write 전략을 통해 미리 유저의 피드를 materialize 하여 조회시 빠르게 반환
정렬 쿼리 최적화 (YouTube 검색 결과)
SELECT * FROM videos WHERE category = 'music' ORDER BY views DESC LIMIT 100;views는 자주 변동됨 → 인덱스 유지 비용이 큼정렬 쿼리는 인덱스를 사용하지 못하면 전량 읽고 메모리에서 정렬함
해결법
인기 콘텐츠는 별도 테이블에 주기적 Snapshot 저장
hot_videos(category, views)테이블 생성 후 캐싱실시간성과 정확도 사이의 Trade-off 존재
범위 조회 쿼리 최적화 (DynamoDB 포함)
DynamoDB에서는 Partition Key + Sort Key 조합을 잘 활용해야 함
SELECT * FROM Messages WHERE user_id = 'abc' AND timestamp BETWEEN 100 AND 200;Partition Key:
user_idSort Key:
timestamp
이런 구조를 사용하면, DynamoDB는 특정 파티션에 대해서만 범위 검색을 수행하고 다른 파티션은 건드리지 않음. B-tree가 아닌 LSM 기반이지만, 쓰기 성능 최적화 측면에서 우수.
Trade-off와 설계 결정
전략
인덱스 추가
조회 속도 증가
쓰기 성능 저하, 공간 증가
조인 최소화 또는 분해
단순 쿼리로 빠른 성능
데이터 중복 또는 정합성 이슈
캐싱(Redis 등)
읽기 속도 극대화
실시간성 부족, TTL 관리 필요
비정규화 (NoSQL)
빠른 조회 성능
업데이트 시 일관성 문제 발생
실전 설계를 위한 사고 방식
쿼리 패턴을 먼저 파악할 것.
읽기 중심인가? 쓰기 중심인가?
데이터를 어떻게 저장해야 빠르게 읽을 수 있을지를 설계에서 고려할 것.
인덱스는 만능이 아니다
쓰기 부하를 줄이기 위한 캐시, 분산 전략도 함께 고려할 것.
DB가 내부적으로 어떻게 쿼리를 수행하는지를 이해하면, 성능 병목의 원인을 빠르게 파악할 수 있다