
DBMS 완전 정복 시스템 구성부터 쿼리 최적화까지 [3]
Hadoop 과 Cassandra 그리고 Time-Series DB에 대해서.

Hadoop 기반 분산 저장/분석 시스템
Hadoop 에코시스템은
분산 파일 시스템인 HDFS와
병렬 처리 모델인 MapReduce를 기반으로,
대규모 데이터 저장 및 배치 분석을 위한 플랫폼을 제공합니다.
전통적인 RDBMS가
소수의 노드에서 OLTP 에 사용되는 반면,
Hadoop은 저렴한 다수의 노드를 묶어
페타바이트(PB)급 데이터까지도 분산 저장하고,
효율적으로 일괄 처리할 수 있도록 설계되었습니다.
또한, Hadoop은 스케일 아웃(scale-out) 구조에 최적화되어 있어,
노드를 추가함으로써 성능과 저장 용량을 선형적으로 확장할 수 있습니다.
특히, 반구조적 데이터(JSON 등)나
비정형 데이터(로그, 이미지, 영상 등)도 자유롭게 저장할 수 있기 때문에,
데이터 레이크(data lake) 구축의 핵심 기술로 널리 활용됩니다.
Data Lake란?
- 정형, 반정형, 비정형 데이터를 원시(raw) 형태로 저장할 수 있는 대규모 저장소
스케일 업 (scale-up) 이란?
- 기존 서버를 더 좋은 CPU, RAM, SSD 등으로 업그레이드 (서버 1대를 더 비싼 고성능 머신으로 바꿈)
스케일 아웃 (scale-out) 이란?
- 서버의 수를 늘려 시스템을 확장 (서버 10대를 20대로 늘려 처리량을 분산)
노드를 추가함으로써 성능과 저장 용량을 선형적으로 확장할 수 있다?
- 서버(노드)를 한 대, 두 대씩 더할수록 거의 비례해서 성능(처리 속도)과 저장 공간이 늘어난다는 의미입니다.
노드를 n대 추가하면 n배 저장 가능
노드 수가 2배 → 성능도 2배,
노드 수가 3배 → 저장 용량도 3배
로 비례하게 증가한다는 뜻입니다.
이걸 반대로 말하면, 어떤 시스템은 노드를 더 붙여도 성능이 거의 안 오르거나, 오히려 느려지는 경우도 있는데, Hadoop은 이런 문제가 없이 효율적으로 확장되도록 설계 되었다는 뜻이에요.
MapReduce란?
MapReduce는 아주 큰 데이터를 여러 컴퓨터에서 동시에 나눠서 처리하는 방법이에요.
말 그대로 Map(분산 처리) → Reduce(결과 합치기) 단계로 나뉘죠.
예시로 쉽게 이해해보기
예를 들어 웹사이트의 로그 1억 건이 있다고 해볼게요.
우리는 이걸 IP 주소별로 접속 횟수를 세고 싶습니다.
1. Map 단계 - 쪼개서 처리하기
1억 개의 로그를 여러 컴퓨터가 나눠서 읽습니다.
각 로그를 보고 “이 IP가 한 번 접속했네!” →
<IP, 1>형식으로 기록합니다.
2. Reduce 단계 - 같은 IP끼리 더하기
Map 단계에서 나온
<IP, 1>데이터를 같은 IP끼리 모읍니다.그 다음
1 + 1 + 1 + ...이렇게 합쳐서 총 접속 횟수를 계산합니다.
→ 결과는<IP, 1280>,<IP, 325>, …
정렬, 조인도 가능
단순한 합계뿐만 아니라,
여러 데이터를 묶어서 정렬, 조인(join) 같은 복잡한 작업도 가능해요.
단, 이런 작업도 Map → Reduce 조합으로 만들어야 해요.
단점
MapReduce는 한 번에 많은 데이터를 처리하긴 좋은데,
작업 시작~끝까지 오래 걸려요. (→ "대기 시간 높음", 즉 실시간 아님)
주요 구성 요소
HDFS
Hadoop Distributed File System은 파일을 블록 단위로 분산 저장하고,
각 블록을 기본 3중 복제하여 노드 장애에도 데이터 손실 없이 동작합니다.
예를 들어 1TB 크기의 파일을 업로드하면 HDFS가 이를 128MB 블록 여러 개로 쪼개 클러스터 전체에 저장하고, 각각의 블록을 서로 다른 3개 노드에 복제해둡니다. 한 노드가 다운되어도 다른 노드에 블록 복제본이 있어 지속적으로 운영이 가능하며, 이는 고가용성(High Availability)과 내결함성(fault tolerance)의 기반이 됩니다.
MapReduce
대량의 데이터를 병렬 처리하는 프로그래밍 모델로, 맵(Map) 단계에서 데이터를 분산 처리하고 리듀스(Reduce) 단계에서 결과를 집계합니다. 예를 들어 웹 로그 1억 건을 IP별로 집계하려면, 맵 함수가 로그 블록들을 병렬로 읽어
<IP, 1>카운트를 만들고, 리듀스 함수가 같은 IP끼리 합산합니다. 이러한 단순 모델을 조합하여 정렬, 조인 등 복잡한 연산도 수행할 수 있습니다. MapReduce 작업은 배치로 동작하여 대기 시간이 높지만 대량 데이터를 한번에 처리하는 데 강합니다. 최근에는 맵리듀스보다 빠른 Apache Spark가 메모리 기반 처리를 통해 Hadoop 환경의 주요 처리엔진으로 부상했지만, 기본 개념은 맵리듀스와 유사합니다.
YARN
Hadoop의 클러스터 리소스 관리 및 스케줄러로, 여러 작업이 노드들에 적절히 할당되도록 제어합니다.
데이터 질의 레이어
Hive, Pig 등은 맵리듀스 위에서 동작하는 고급 언어(SQL 유사 또는 스크립트)로, 개발자가 SQL 질의를 작성하면 내부적으로 맵리듀스 잡으로 변환해 실행합니다. 이를 통해 데이터 분석가가 분산 파일 데이터를 SQL로 질의할 수 있게 해주며, 대용량 데이터 웨어하우징을 가능케 합니다.
Hadoop 기반 시스템의 장점은 거의 무제한에 가까운 확장성과 저비용으로 방대한 데이터 저장이 가능하다는 것입니다. 구조화되지 않은 로그, 이미지, 텍스트를 모두 HDFS에 넣어둘 수 있고, 필요시 맵리듀스 잡이나 Spark 잡으로 분석하여 가치 있는 정보를 추출하는 스키마-온-리드 방식의 데이터 처리가 가능합니다. 반면 단점으로는 실시간 처리의 어려움과 높은 조회 지연이 꼽힙니다. 최소 수십 초~수분 단위의 배치 처리이므로, 즉각적인 사용자 질의 응답보다는 오프라인 분석용에 가깝습니다. 또한 설정 및 운영이 복잡하고, 소규모 데이터 처리에는 오히려 비효율적입니다. 따라서 하둡은 "한 번에 거대한 데이터셋을 처리"하는 용도로 특화되어 있고, 이것이 필요한 상황(예: 일일 사용자 로그 통계 산출, 머신러닝 모델 학습 데이터 준비)에서 활용됩니다.
Facebook, Yahoo 사례
실제로 Facebook은 하둡 기반으로 매일 수백 TB의 사용자 로그를 처리하고 Hive로 통계 분석을 해왔으며, Yahoo나 Twitter도 거대한 이벤트 데이터를 하둡 클러스터에서 분석했습니다. 현대에는 클라우드 기반 데이터레이크 + Spark + Presto(Hive) 조합으로 진화했지만, 기본 아이디어는 유사합니다.
인터뷰 팁
면접에서 데이터 파이프라인이나 빅데이터 아키텍처를 묻는다면, Hadoop/HDFS 같은 분산 스토리지와 배치 처리의 개념을 언급하는 것이 좋습니다. 특히 스토리지와 컴퓨팅 분리(예: AWS S3 + EMR/Spark) 트렌드도 있지만, 여전히 Hadoop 개념 이해는 빅데이터 설계의 밑바탕입니다.
시계열 데이터베이스 (Time-Series DB)
시계열 데이터베이스는 시간에 따라 변화하는 데이터(예: 센서 값, 주가, 서버 모니터링 지표 등)를 효율적으로 저장하고 조회하기 위해 특화된 DBMS입니다.
대표적으로 InfluxDB, TimescaleDB, Prometheus 등이 있습니다. 이러한 DB는 공통적으로 타임스탬프를 기본 인덱스로 사용하고, 시간 순으로 데이터를 빠르게 쓰고 읽을 수 있도록 설계되었습니다.
시계열 데이터는 보통 데이터 양이 방대하고 삽입 빈도가 매우 높으며, 최근 데이터에 대한 신속한 통계와 과거 장기 추세 분석 둘 다 중요합니다.
이를 위해 시계열 DB는 일반적인 DB와는 다른 몇 가지 특징을 제공합니다
압축 및 스토리지 최적화
시계열 데이터는 연속된 시간 범위 내에서 값 변화 패턴이 있어 압축 알고리즘으로 저장 공간을 크게 줄입니다. 예를 들어 TimescaleDB는 일정 시간 단위로 파티션을 나누고 각 파티션별로 압축을 적용하여, 같은 숫자 패턴이나 반복되는 태그 값은 차분 저장합니다. 이를 통해 수십억 행의 시계열 데이터를 저렴한 스토리지 비용으로 보관할 수 있습니다.
다운샘플링(rollups) 및 데이터 수명주기 관리
모든 시계열 데이터를 영구 보존하지 않고, 오래된 데이터는 요약본만 남기는 전략이 흔합니다. 시계열 DB는 일정 기간 지난 세부 데이터를 자동으로 삭제하고 요약 통계로 대체하는 정책(continuous query, retention policy)을 지원합니다. 예를 들어 최근 1개월 치는 1분 단위 데이터, 1년 이상 지난 데이터는 1시간 단위 평균으로 간략화하는 식입니다. 이러한 자동 만료 및 요약 기능은 일반 DB에서 수동으로 구현하려면 어려운 작업이지만, TSDB에서는 기본 제공됩니다.
시계열 전문 질의
시간 창(Window)별 집계, 미리 정해진 기간별 평균/최대/최소, 미세한 시간해상도의 패턴 검색 등의 연산이 최적화되어 있습니다. 예를 들어 메모리 사용량 추이를 월별로 요약하거나, 올해와 지난해 같은 기간의 지표 비교 같은 질의가 효율적입니다. 이는 일반 키-값 스토어나 RDBMS에서 시간 조건으로 수억 건을 스캔해야 하는 작업을, TSDB는 시간 기반 파티셔닝과 인덱스 덕분에 수백 밀리초 내에 수행할 수 있음을 의미합니다.
TimescaleDB는 Postgres 확장 형태로 관계형 질의와 시계열 최적화를 겸비했고, InfluxDB는 독자 쿼리 언어를 제공하지만 MQTT 등 모니터링 표준 스택과 통합이 잘 되어있는 등 각각 장단점이 있습니다. 금융(주식 체결 내역, 시세), IoT(센서 스트림), DevOps(시스템 모니터링, 로그) 등에서 널리 쓰이며, 최근 Prometheus + Grafana 같은 모니터링 스택의 인기로 TSDB가 필수 구성요소로 자리잡았습니다.
요약하면, 시계열 DB는 시간 축을 중심으로 최적화된 특수 목적 DB입니다. 면접에서 "모니터링 시스템을 설계하라"는 등의 질문에, 일반 DB가 아닌 TSDB를 언급하면 깊은 이해를 보여줄 수 있습니다. 이때 “왜 시계열 DB가 필요한가”에 대해 대량의 시계열 데이터에 대한 빠른 집계 질의와 보관 전략을 자동화해주기 때문임을 설명하면 좋습니다.
시나리오#1 스마트 팩토리 실시간 모니터링 시스템
목적
공장 내 수천 개의 센서로부터 들어오는 실시간 데이터를 수집하고,
이상 징후를 탐지하며,
과거 데이터를 기반으로 유지보수와 효율성 분석을 자동화.
사용하는 이유
수억 건의 실시간 센서 데이터를 빠르게 쓰기 - 고속 쓰기 최적화 (Write-optimized)
1개월 치의 10초 단위 데이터를 1분 단위로 요약 - 자동 다운샘플링 정책 지원
"최근 7일간 온도 변화가 가장 컸던 설비 TOP 5" 질의 - 시계열 집계 함수로 빠르게 처리
장기 데이터 보관 비용 - 압축 저장 + Retention Policy
"1000개의 서버에서 CPU/Memory 사용량을 수집해서 모니터링 시스템을 구축해야 한다면 어떻게 설계할 것인가?"해설
시계열 데이터 특성이 강하므로 일반적인 RDBMS보다는 InfluxDB나 TimescaleDB 같은 시계열 DB를 사용하겠습니다. 각 서버의 메트릭을 태그 기반으로 저장하고, 일정 기간 이후에는 데이터를 자동으로 요약해 보관합니다. 이를 통해 대시보드에서 실시간 모니터링과 장기 분석을 모두 지원할 수 있습니다.
시스템 디자인 인터뷰를 위한 Cassandra
데이터베이스는 백엔드 시스템 아키텍처의 핵심입니다. 그중에서도 Apache Cassandra는 가장 강력하고 확장 가능한 NoSQL 데이터베이스 중 하나입니다.
원래 Facebook이 인박스 검색 기능을 확장하기 위해 만든 Cassandra는 현재 Discord, Netflix, Apple, Bloomberg 등에서 사용되며 시스템 디자인 인터뷰에서도 자주 등장합니다.
Cassandra의 데이터 모델과 구조
분산, 복제, 가용성 보장 방식
LSM Tree 기반의 쓰기/읽기 처리 흐름
Gossip 프로토콜, 일관성 수준, 장애 복구
Discord / Ticketmaster 실사례 분석
Cassandra 기본 개념
데이터 모델
Cassandra는 분할된 와이드 컬럼 저장소 구조를 따릅니다.
Keyspace - 최상위 컨테이너 (Postgres의 데이터베이스와 유사)
Table - 행을 저장하는 테이블
Row - 고유한 Primary Key로 식별되는 데이터
Column - 키-값 쌍이며, 각 열에는 타임스탬프 메타데이터가 존재
Cassandra는 유연한 스키마를 지원하며, 각 행이 서로 다른 열을 가질 수 있습니다.
예시
{
"keyspace1": {
"table1": {
"row1": { "col1": 1, "col2": "abc" },
"row2": { "col1": 2, "col3": 3.0 }
}
}
}Primary Key
Primary Key = Partition Key (+ Clustering Key)
Partition Key - 데이터를 어떤 노드에 저장할지 결정
Clustering Key - 파티션 내에서의 정렬 순서를 결정
CREATE TABLE t (
a TEXT,
b TEXT,
PRIMARY KEY ((a), b)
);파티셔닝과 데이터 분산
파티셔닝과 데이터 분산에 대해 알아보기전 Consistent Hashing 에 대한 개념을 짚고 넘어가도록 하겠습니다.
Consistent Hashing(일관된 해싱)
원형 링(Circle 또는 Hash Ring) 구조를 사용합니다.
- 키(key)와 노드(node)를 같은 해시 함수로 해싱하여 0~2³² 범위의 원형 공간에 배치합니다.
- 키는 자기보다 시계방향으로 가까운 노드에 저장됩니다.
- 노드가 추가되면, 일부 키만 새로운 노드로 이동하면 됨 → 전체 재분배가 아님.
분산 시스템에서 데이터를 균형 있게 분산 저장하고, 노드의 추가/삭제 시 데이터 이동량을 최소화하기 위한 해싱 전략입니다. 대규모 분산 DB (예: Cassandra, DynamoDB)나 캐시 시스템 (예: Redis Cluster, Memcached)에서 매우 중요한 개념입니다.
기존 해싱의 문제점
기존 방식 (예: hash(key) % N 방식)은 아래와 같은 문제가 있습니다.
N(노드 수)이 바뀌면, 전체 데이터의 해시값이 바뀌어 재분배가 필요함 → 대부분의 데이터가 이동.
예: 3개 노드 → 4개로 증가하면, 거의 모든 키의 hash % 3 → hash % 4가 달라짐.
작동 방식 예시
예를 들어 hash(key) 결과가 40이라고 할 때,
Ring에 있는 노드의 해시값이 10, 50, 90이면,
key는 50번 노드에 저장됨 (40보다 큰 가장 가까운 노드).
노드 추가/삭제 시 데이터 이동 최소화
- 노드 추가 - 해당 위치로 hash된 key 일부만 새 노드로 이동
- 노드 삭제 - 해당 노드가 처리하던 key만 이웃 노드로 이동
전체 데이터 중 일부만 이동하므로 성능 저하와 부하 분산 문제가 줄어듦
언제 사용되나요?
- DynamoDB / Cassandra - 데이터를 파티셔닝할 때 사용
- Redis Cluster / Memcached - 캐시 분산 저장
- 분산 파일 시스템 (e.g., Ceph) - 파일 블록 분산 위치 지정
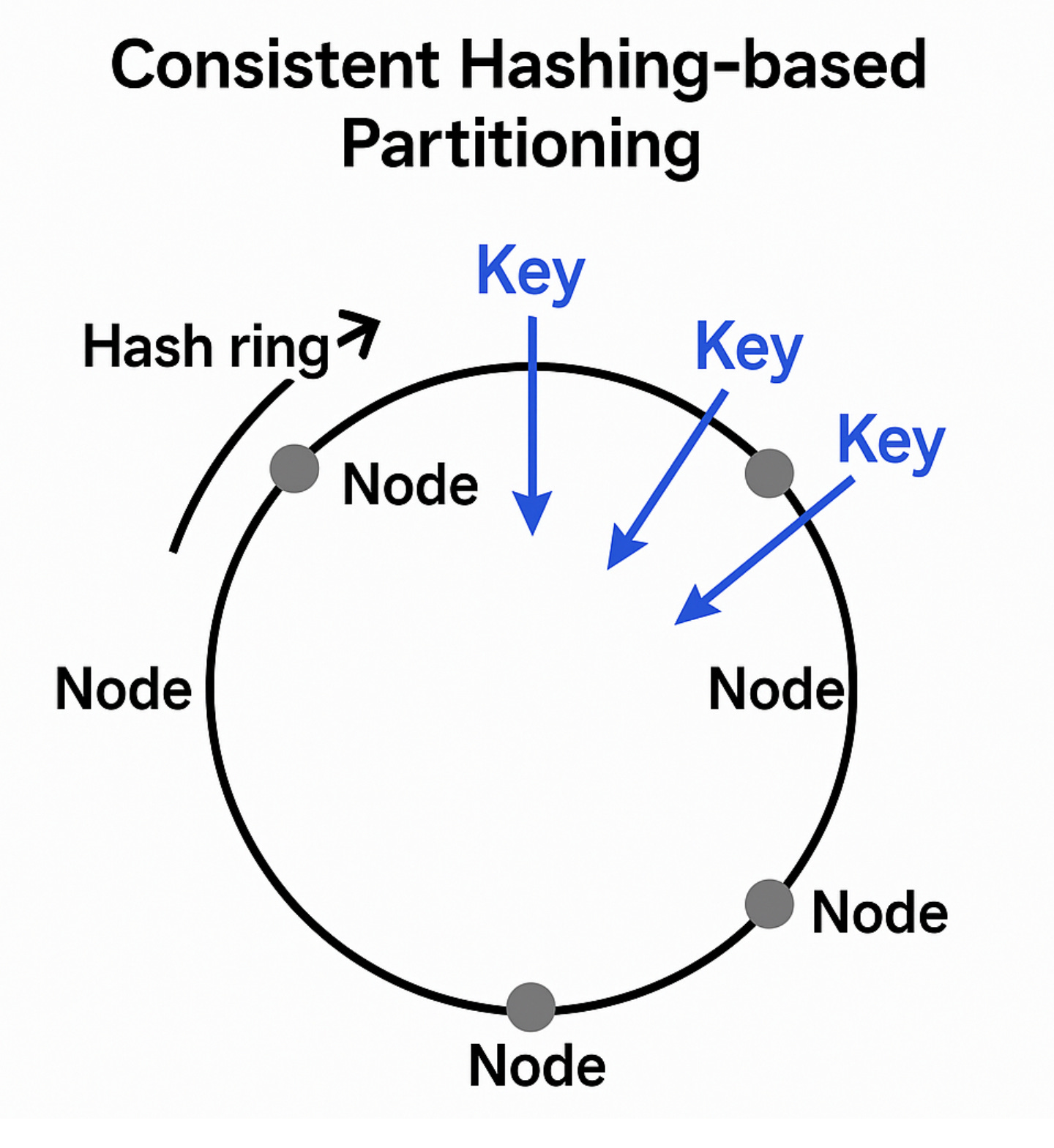
Cassandra는 수평 확장을 위해 Consistent Hashing 기반 파티셔닝을 사용합니다.
노드들은 가상 링 구조에 배치됨
Partition Key 를 해싱하여 특정 vnode에 할당
하나의 물리 노드가 여러 vnode를 소유하여 부하를 분산시킴
장점
노드 추가/제거 시 리밸런싱 최소화
예측 가능한 분산 처리
복제
Cassandra는 고가용성을 위해 데이터를 여러 노드에 복제합니다.
SimpleStrategy- 테스트용 간단한 구성NetworkTopologyStrategy- 데이터 센터/랙 인식 복제 전략
예시
ALTER KEYSPACE ks WITH REPLICATION = {
'class': 'NetworkTopologyStrategy',
'dc1': 3,
'dc2': 2
};일관성 수준 (Consistency)
Cassandra는 최종적 일관성(Eventual Consistency) 모델을 따르며, 읽기/쓰기 요청마다 일관성 수준을 지정할 수 있습니다:
ONE,QUORUM,ALL등QUORUM: 과반수(n/2+1)가 응답 시 성공 → 읽기/쓰기에 모두 적용하면 읽기 시 항상 최신 쓰기를 읽을 수 있음
트랜잭션은 없으며, 행 수준의 원자성만 보장됩니다.
저장 구조 - LSM Tree 기반
Cassandra는 Log-Structured Merge Tree (LSM Tree)를 사용하여 빠른 쓰기를 제공합니다.
Commit Log - Write-Ahead 로그
Memtable - 메모리 내 정렬된 버퍼
SSTable - 디스크에 저장되는 불변 파일
쓰기
Commit Log에 기록
Memtable에 저장
일정 조건 시 SSTable로 플러시
읽기
Memtable → Bloom Filter → 최신 SSTable부터 조회
Compaction - SSTable을 병합하고 삭제된 데이터(tombstone)를 제거
Gossip 프로토콜
Cassandra 노드들은 Gossip 프로토콜을 통해 클러스터 상태를 공유합니다.
P2P 방식으로 상태 교환
Seed 노드를 통해 클러스터 전체 연결 보장
버전 및 생성 정보 (벡터 클럭) 사용
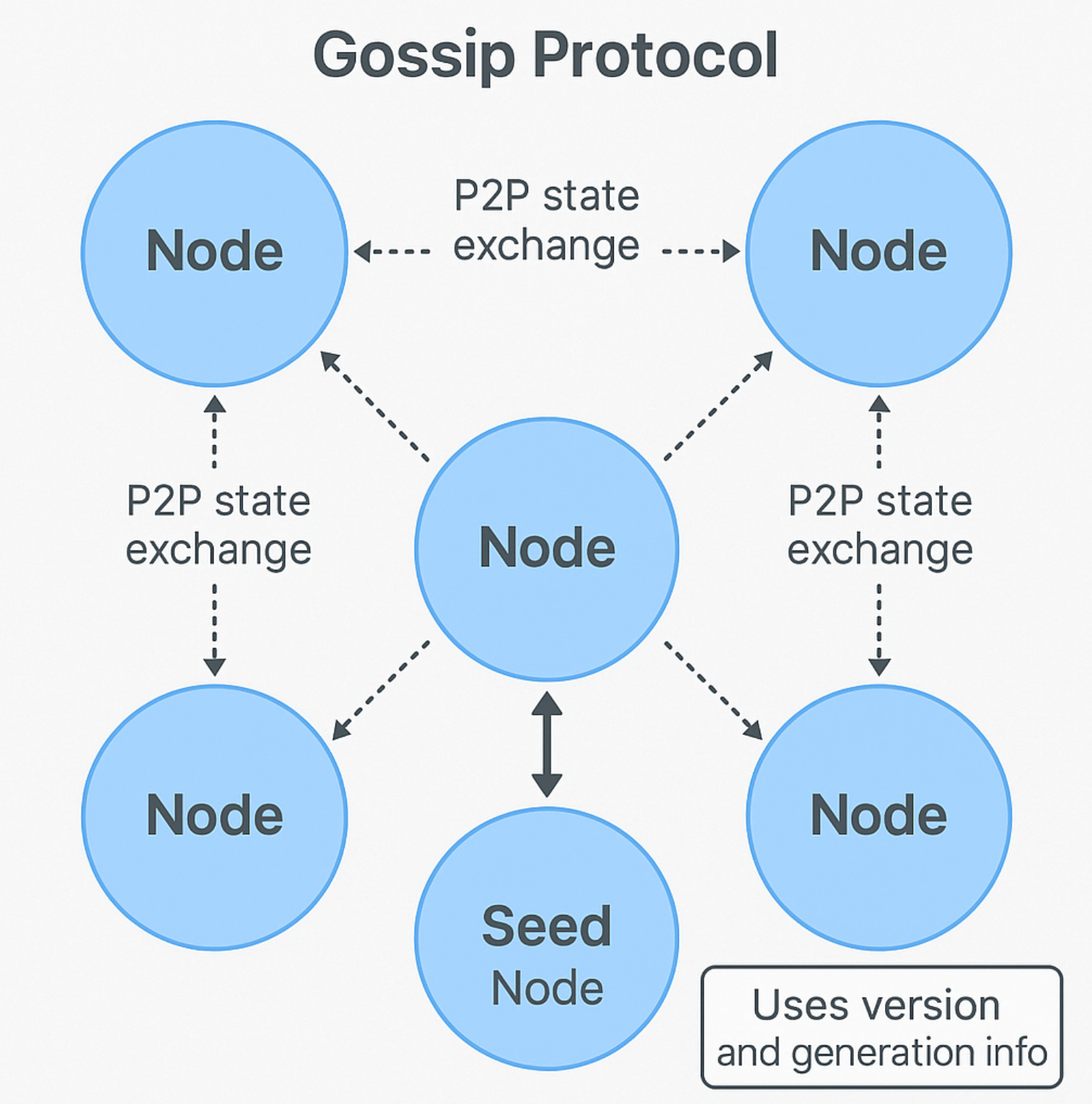
Gossip 프로토콜이란?
Cassandra는 중앙 서버 없이 모든 노드가 서로 정보를 주고받는 P2P(피어 투 피어) 구조입니다. 이때 노드 간에 클러스터의 상태(누가 살아 있고, 누가 죽었고, 어떤 데이터가 있는지 등)를 주기적으로 교환하는 방식이 바로 "Gossip 프로토콜"입니다.
어떻게 동작하나요?
1. P2P 방식
- 각 노드는 주기적으로 다른 노드 중 1~2개를 랜덤으로 선택하여 현재 상태 정보를 교환합니다.
- 이 정보에는 “내가 지금 살아있다”, “이 노드도 최근에 확인했는데 살아있더라” 같은 정보가 포함됩니다.
즉, 마치 소문(Gossip) 퍼지듯, 클러스터 전체에 정보가 퍼집니다.
Seed 노드 역할
- Cassandra 클러스터를 처음 시작할 때, Seed 노드는 연결의 중심 역할을 합니다.
- 모든 노드가 최소한 이 Seed 노드와는 연결을 시도하기 때문에, 새로운 노드가 클러스터에 들어와도 전체 연결성이 깨지지 않고 유지됩니다.
벡터 클럭 (Vector Clock) 으로 충돌 방지
모든 상태 정보에는 Generation (생성 시점) - 노드가 시작된 시간
Version (논리적 시계) - 변경 횟수가 포함되어 있어요.
이를 통해 더 최신 정보인지 판단할 수 있으며, 중복/오래된 정보는 무시하게 됩니다.
왜 중요한가요?
- 어떤 노드가 다운되었는지 빠르게 알 수 있습니다.
- 데이터 복제나 읽기/쓰기 경로를 동적으로 조정할 수 있습니다.
- 중앙 제어 서버 없이도 고가용성, 확장성 유지가 가능합니다.
장애 복구와 견고성
장애 감지 - Phi Accrual Failure Detector
Hinted Handoff - 실패한 노드를 위한 임시 쓰기 저장
Read Repair - 읽기 중 발견한 불일치 자동 수정
실제 시나리오 - Discord 메시지 저장
CREATE TABLE messages (
channel_id BIGINT,
bucket INT,
message_id BIGINT,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);bucket-10일 단위로 나눠 큰 파티션을 방지message_id- Snowflake ID로 정렬 → 최신 메시지 조회 최적화
실제 시나리오 - Ticketmaster 좌석 시스템
CREATE TABLE tickets (
event_id BIGINT,
section_id BIGINT,
seat_id BIGINT,
price BIGINT,
PRIMARY KEY ((event_id, section_id), seat_id)
);파티션 키 - (event_id, section_id) → 좌석 분산
이벤트 전체 조회는 별도 테이블
event_sections를 통해 해결
고급 기능
Materialized Views - 자동 비정규화 테이블 생성
Storage Attached Indexes (SAI) - 전역 Secondary Index
Elasticsearch/Solr 연동 가능
면접에서 Cassandra 사용할 때
적합한 경우
높은 쓰기 처리량 필요
고가용성이 중요한 시스템
명확한 접근 패턴이 있는 경우
부적합한 경우
트랜잭션 또는 강한 정합성이 필요한 경우
JOIN, 복잡한 쿼리 필요 시
Cassandra는 쓰기 중심의 대규모 분산 시스템에서 탁월한 성능을 보이는 NoSQL 데이터베이스입니다. LSM Tree, Consistent Hashing, Gossip, Tunable Consistency 등 핵심 개념을 이해하고, 쿼리 기반 데이터 모델링으로 설계한다면 강력한 시스템을 만들 수 있습니다.
FAANG 인터뷰나 실무 설계에서 Cassandra를 전략적으로 활용할 줄 아는 것은 큰 강점이 됩니다.
각 유형 DB의 장단점 및 트레이드오프
위에서 다양한 DB 유형을 살펴보았는데, 이제 주요 특성별로 장단점을 비교해보겠습니다. 시스템 설계에서는 모든 요구를 한 가지 기술로 충족할 수 없고, 항상 몇 가지 속성을 얻기 위해 다른 면을 희생(trade-off)한다는 관점이 중요합니다. 아래는 성능, 확장성, 정합성, 비용, 개발 복잡도 측면에서 각 DB를 비교한 내용입니다.
성능
성능은 사용 패턴에 따라 달라집니다. 관계형 DB는 복잡한 조인 질의나 다중 레코드 트랜잭션 성능이 우수하지만, 수평 분산이 안 된 상태에서 단일 노드 처리량은 하드웨어 한계에 묶입니다.
Key-Value 스토어는 불필요한 오버헤드를 제거하고 단순 조회/갱신에 최적화되어 메모리 내에서는 마이크로초 단위 응답도 가능하며, 분산 시 노드 수 증가에 따라 선형 성능 향상을 기대할 수 있습니다.
Document/Column DB도 인덱싱을 잘 하면 특정 패턴 질의는 매우 빠르지만, 데이터가 분산된 상황에서 교차 샤드 질의는 성능이 떨어질 수 있습니다. Elasticsearch는 텍스트 검색, 집계 쿼리는 뛰어나나 일관된 최신 데이터 조회가 필요한 OLTP에는 부적합합니다.시계열 DB는 쓰기 성능을 극대화(예: 초당 수백만 포인트 삽입)하면서도 최근 범위 조회는 메모리에 캐시하여 빠르게 제공합니다. Hadoop은 배치 처리 성능은 높지만 (망치로 크기 큰 못을 박듯이), 단건 조회 성능은 매우 낮아 실시간 질의에는 아예 쓰이지 않습니다.
확장성(Scalability)
관계형 DB는 일반적으로 수직 확장(Scale-up)에 의존하므로 고성능 서버가 필요하며, 어느 정도 이상은 확장이 어려워집니다. (물론 분산 SQL DB도 있지만 전통적 RDBMS 맥락에서는).
NoSQL DB들은 설계 단계부터 수평 확장(Scale-out)을 염두에 두고 만들어져, 다수 노드에 분산함으로써 용량과 처리량을 거의 제한 없이 늘릴 수 있습니다.
예를 들어, Cassandra나 MongoDB는 몇 노드에서 수백 노드까지 선형 확장이 가능하며, DynamoDB는 완전관리형으로 내부에서 파티셔닝 자동 관리로 사용자에게 무한 확장처럼 보이게 합니다. Elasticsearch 역시 샤드 수 증설과 노드 추가로 데이터를 분산 저장하여 PB급 로그도 다룰 수 있습니다. 그래프 DB는 데이터가 촘촘히 엮여있을 때 샤딩이 어려워 확장성이 떨어질 수 있지만, 최근 네이티브 멀티-서버 그래프DB (Neo4j Fabric 등)도 나옵니다. Hadoop(HDFS)은 설계상 수천 노드까지 확장 가능하며 페타바이트~엑사바이트 데이터를 저장/처리하는데 쓰입니다. 정리하면, NoSQL/Hadoop 계열은 노드를 추가하는 것이 곧 성능/용량 확장으로 이어지는 반면, 관계형 DB는 임계점을 넘어서면 샤딩 등 특단의 조치가 필요하다는 차이가 있습니다.
정합성(Consistency)
ACID를 엄격히 지키는 관계형 DB는 강한 일관성(Strong Consistency)을 제공하여 한 트랜잭션 내에서는 데이터 변형이 원자적으로 처리되고, 커밋 후 즉시 모든 읽기에서 보입니다.
반면 많은 분산 DB들은 CAP 이론에 따라 일정 수준의 정합성 손실을 감수합니다. Casssandra, Dynamo 등의 AP 지향 DB는 네트워크 분할이나 일부 노드 장애 시에도 가용성을 유지하는 대신, 잠깐 동안 복제본 간 데이터가 달라질 수 있음을 허용합니다. 이것이 Eventual Consistency이며, 결국 데이터를 리컨실(reconcile)하여 수렴시킵니다.
MongoDB나 HBase 등 CP 지향 DB는 쓰기 가용성을 희생해서라도 데이터 정합성을 더 보장하려는 쪽에 가깝지만, 그렇다고 RDB만큼 강력히 일관한 것은 아닙니다 (일반적으로 Primary-Secondary 구조에서 Primary 장애 시 Secondary 승격 동안 쓰기 불가 등). NewSQL DB들은 정합성과 확장성 둘 다 잡으려 하지만 (예: Spanner는 글로벌 정합성 제공), 구현이 매우 복잡합니다. 정합성 측면에서는 RDBMS가 즉각적이고 철저한 무결성으로 최고점을, NoSQL은 궁극적 일관성으로 약간 낮은 점수를 받는다고 볼 수 있습니다.
애플리케이션 요구사항에 따라 강한 정합성 vs. 최종 정합성 선택이 중요한데, 인터뷰에서는 “트랜잭션이 중요하면 RDBMS, 데이터 양이 크고 성능이 중요하면 NoSQL (단, 정합성은 적절히 보완)” 같은 언급이 필요합니다.
비용(Cost)
여기에는 금전적 비용과 복잡도 비용 둘 다 고려됩니다. 상용 RDBMS(Oracle 등)는 라이선스 비용이 매우 높을 수 있고, 오픈소스라도 고사양 단일 서버 비용이 커집니다.
반면 대부분 NoSQL은 오픈소스이며, x86 범용 서버를 여러 대 사용하는 구조라 초기 하드웨어 비용을 낮출 수 있습니다. 그러나 분산 시스템을 직접 운영하면 인건비(운영 복잡성)가 상승합니다.
클라우드로 간다면, 관리형 서비스 (Aurora, DynamoDB, BigQuery 등)의 비용 모델을 따르게 되는데, 필요 이상으로 쓰지 않도록 스케일링 전략을 잘 세워야 합니다. 또한 데이터 일관성 유지를 위한 어플리케이션 복잡도도 개발 비용으로 볼 수 있습니다. 예를 들어 관계형 DB에서는 참조 무결성, 트랜잭션으로 해결될 문제가, NoSQL에서는 개발자가 중복 데이터 관리, 충돌 처리 로직을 짜야 할 수 있습니다.
이 역시 비용이라 할 수 있습니다. Hadoop 같은 시스템은 오픈소스로 구축시 하드웨어 비용은 낮출 수 있어도 (저가 디스크 수백 개), 운영 전문성이 필요하며, 클라우드 EMR/Spark를 쓰면 편의 대신 비용이 증가합니다.
면접에서 비용 얘기가 나오면, “스케일 아웃은 초기 비용 낮추지만 운영 복잡성 높임”, “Managed 서비스는 편하지만 벤더 종속과 금전 비용 큼” 등을 언급하면 성숙한 시각을 보여줄 수 있습니다.
복잡도(Development Complexity)
개발 생산성은 때로 DB 선택에 큰 영향을 줍니다. 관계형 DB와 SQL 조합은 수십 년간 검증되어 온 표준이고, 개발자 대부분이 친숙하며 튜닝 노하우도 많습니다.
따라서 요구사항에 맞고 성능 상 문제가 없다면 RDBMS를 우선 채택하는 것이 개발을 빠르게 할 수 있는 길입니다. 반면 NoSQL은 각기 다른 API와 제약을 가지므로 학습이 필요하고, 데이터 모델링도 정규화된 테이블 설계보다 추상적일 수 있습니다.
Document DB는 JSON으로 개발이 쉬운 편이나, Graph DB의 Cypher, Gremlin 같은 질의 언어는 러닝커브가 있을 수 있습니다. 또한 분산 환경 버그(네트워크 지연, 노드 불일치 등)는 재현 및 디버그가 어려워 개발 난이도를 올립니다. 반대로, 특정 문제에 NoSQL이 자연적으로 맞아떨어지는 경우도 있습니다.
예를 들어 JSON API를 만드는 서비스는 처음부터 MongoDB로 시작하면 객체-관계 매핑을 할 필요 없이 JSON 그대로 DB-네트워크로 흘려보내니 편할 수 있습니다. ElasticSearch도 로그 데이터 분석용으로 ELK 스택을 쓰면 몇 주 걸릴 일을 며칠만에 구축 가능합니다.
Hadoop/Spark은 SQL에 익숙한 개발자에겐 진입장벽이 있지만, 데이터 사이언티스트나 분석가에게 대용량 데이터에 대한 강력한 도구를 제공합니다. 결국 복잡도 측면 트레이드오프는, “만만한 기술은 범용성이 떨어지고, 범용적인 기술은 스케일 한계가 있을 수 있다”로 귀결됩니다. 면접에서 이러한 점을 짚으며, “팀의 기술 역량과 유지보수도 고려해 적절한 솔루션을 선택해야 한다”고 언급하면 좋습니다.
다음에서 이어집니다.