
DBMS 완전 정복 시스템 구성부터 쿼리 최적화까지 [2]
시스템 디자인 데이터베이스 설계편 - Elastic Search & Geospatial DB

왜 Elasticsearch인가?
많은 시스템 디자인 문제는 결국 하나의 질문으로 귀결됩니다
“엄청나게 많은 데이터 중에서, 원하는 정보를 얼마나 빠르게 찾을 수 있는가?”
PostgreSQL 같은 관계형 DB도 FULL TEXT INDEX 를 통해 어느 정도까지는 텍스트 검색을 지원합니다. 하지만 데이터가 수백만 건 이상으로 늘어나고, 정렬,필터링,복합 조건 검색 등 요구사항이 복잡해 질수록 성능의 한계를 체감하게 됩니다.
이럴 때 등장하는 것이 Elasticsearch입니다.
실시간 검색, 정렬, 필터링, 랭킹, 자동완성, 페이징 등 거의 모든 검색 관련 요구사항을 해결하기 위해 설계된 전문 검색 엔진입니다.
검색 서비스에 어떻게 적용하는가?
→ 실제 시스템에 어떤 구조로 활용되는지 이해했는가Elasticsearch는 내부적으로 어떻게 동작하는가?
→ 분산 시스템, 인덱싱 최적화, 불변 데이터 구조에 대한 이해도
그 전에 용어에 대한 개념을 짚고 넘어갈 것 입니다.
Node란?
Elasticsearch 클러스터를 구성하는 개별 서버(또는 인스턴스)
하나의 Elasticsearch는 보통 여러 개의 노드로 구성된 클러스터입니다.
각 노드는 역할에 따라 다음과 같이 구분됩니다
Shard란?
하나의 Elasticsearch Index를 여러 조각으로 분산 저장한 단위
Elasticsearch의 Index는 내부적으로 여러 Shard로 나뉘어 저장됩니다.
이 Shard들은 Data Node들에 분산 배치됩니다.
Shard는 다시 Lucene Index로 구성되며, 내부에 Segment들을 포함합니다.
Shard → Lucene Index → Segment란?
Elasticsearch는 데이터 검색을 빠르게 하기 위해 여러 층의 구조로 데이터를 쪼갭니다.
Shard는 하나의 "데이터 조각"입니다.
Elasticsearch의 하나의 Index (예: posts 전체 데이터)는 너무 크기 때문에,
여러 개의 Shard(조각)로 나눠서 여러 서버(Node)에 나눠 저장합니다.
마치 큰 책을 여러 권의 소책자로 나누는 것처럼 생각하면 돼요.
각 Shard는 내부적으로 Lucene Index로 구성돼 있어요.
Elasticsearch는 Lucene이라는 검색엔진을 기반으로 동작해요.
Shard 하나는 결국 Lucene 검색엔진의 인스턴스라고 보면 됩니다.
즉, Shard 안에는 실제 검색을 빠르게 해주는 검색 시스템(Lucene Index)이 들어 있는 거예요.
Lucene Index는 Segment라는 단위로 나뉘어요.
Lucene은 데이터를 한 번에 저장하지 않고, 작은 단위(Segment)로 잘게 나눠서 저장합니다.
Segment는 불변(immutable)이라서, 데이터를 수정하면 새로 만들고, 예전 건 나중에 지웁니다.
이메일을 계속 덧붙여 저장하는 느낌이에요.
나중에 비슷한 Segment끼리 합쳐서 정리(Merge)하기도 합니다.
Index: posts
→ Shard 0 → Node A
→ Shard 1 → Node B
→ Shard 2 (Replica of Shard 0) → Node C 이렇게 되면 검색은 모든 샤드에 병렬로 요청되고, 결과가 Coordinating Node에서 병합되어 응답됩니다.
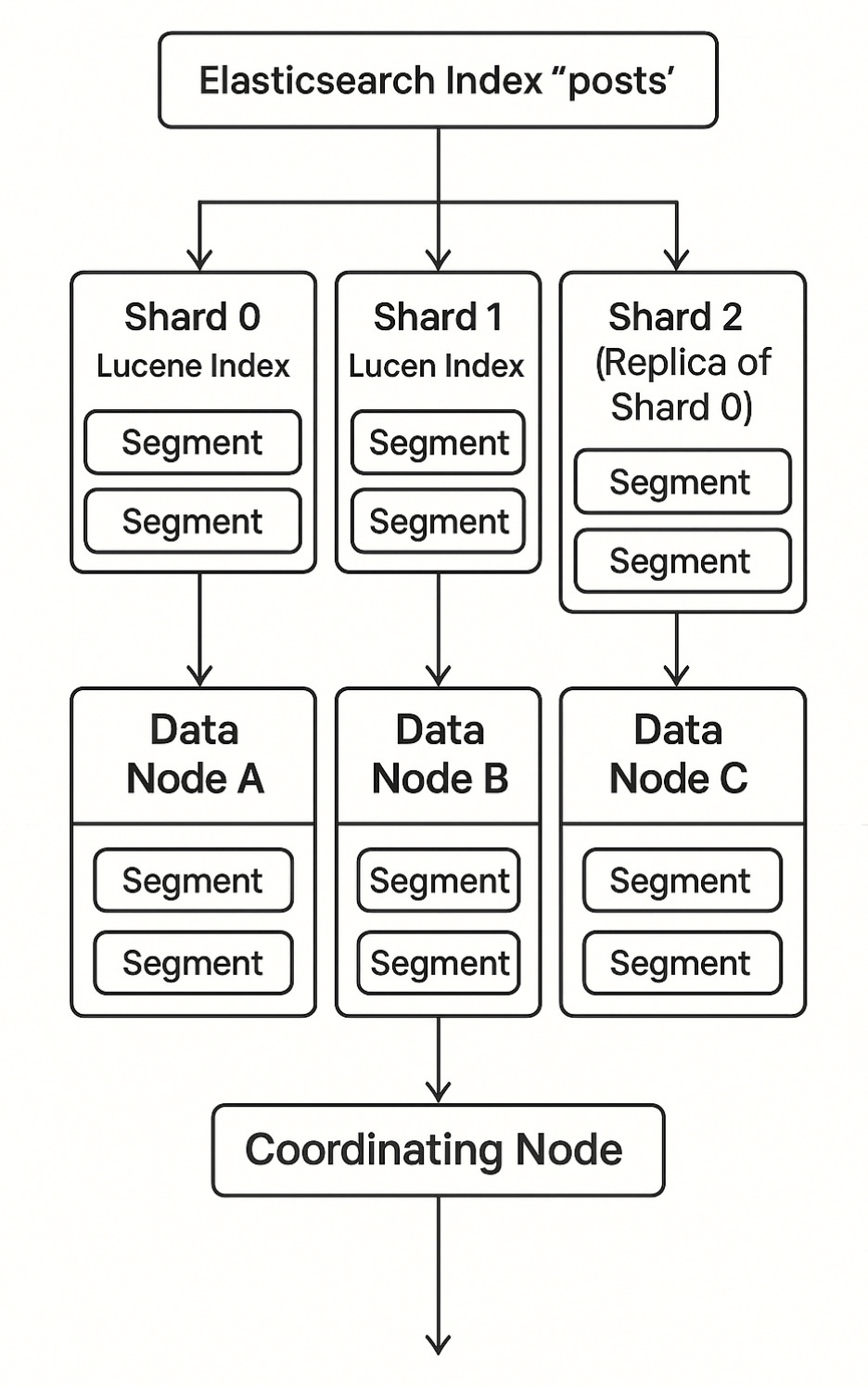
왜 이렇게 나누는가?
노드로 나누면 수평 확장 가능 (스케일 아웃)
샤드로 나누면 하나의 인덱스도 병렬 분산 저장 가능
즉, 노드는 하드웨어/서버 단위이고,
샤드는 데이터를 분산 저장하기 위한 논리적 조각이라고 이해하시면 편합니다.
Shard: 데이터를 분산하기 위한 큰 덩어리
Lucene Index: Shard 안에서 검색을 처리하는 실제 엔진
Segment: Lucene이 데이터를 쪼개서 저장하는 작은 조각
이렇게 계층적으로 잘게 나누고, 병렬로 나눠 저장하고, 인덱스를 잘 만들어 놓기 때문에 Elasticsearch는 수백만 건의 데이터도 몇 밀리초 안에 검색할 수 있는 것 입니다.
Elastic Search
Elasticsearch는 Apache Lucene 위에 구축된 오픈소스 분산 검색엔진입니다.
내부적으로 역색인(Inverted Index) 구조를 사용해 대용량 데이터의 전문 검색을 실시간으로 수행하며, JSON 기반의 유연한 문서 모델을 지원합니다.
기본 구성요소는 다음과 같습니다.
Document - JSON 객체 하나, 예: 책 한 권의 정보
Index - Document의 모음 (DB에서 Table 개념)
Field - JSON 내부의 각 키값 (title, price 등)
Mapping - 각 Field의 자료형과 검색 방식 정의 (Schema 개념)
{
"title": "The Great Gatsby",
"price": 10.99
}RDBMS vs Elasticsearch
관계형 DB에서 LIKE '%keyword%'는 전체 스캔을 동반한 비효율적 연산입니다.
반면 Elasticsearch는 단어 단위로 색인을 구성해 빠르게 검색이 가능합니다.
뿐만 아니라, 집계(Aggregation), 통계 분석, 필터링, 정렬 기능도 탁월하여
로그 분석, 모니터링, 상품 검색, 추천 검색, 자동완성 등 다양한 실시간 검색 시나리오에 활용됩니다.
또한, Elasticsearch는 기본적으로 스키마리스(schema-less)에 가깝고, 수평 확장을 전제로 설계되어 많은 양의 데이터를 샤드(shard)로 분산 저장합니다. 예를 들어 수백만 건의 로그 데이터도 여러 노드에 분산해 저장하고, 검색 시에는 각 노드에서 병렬로 검색 후 결과를 종합합니다. 복제본(replica)도 기본 설정으로 유지하여 고가용성과 검색 성능을 높입니다.
분산 아키텍처 구조
Elasticsearch는 수평 확장형 분산 시스템으로 설계되어 있습니다.
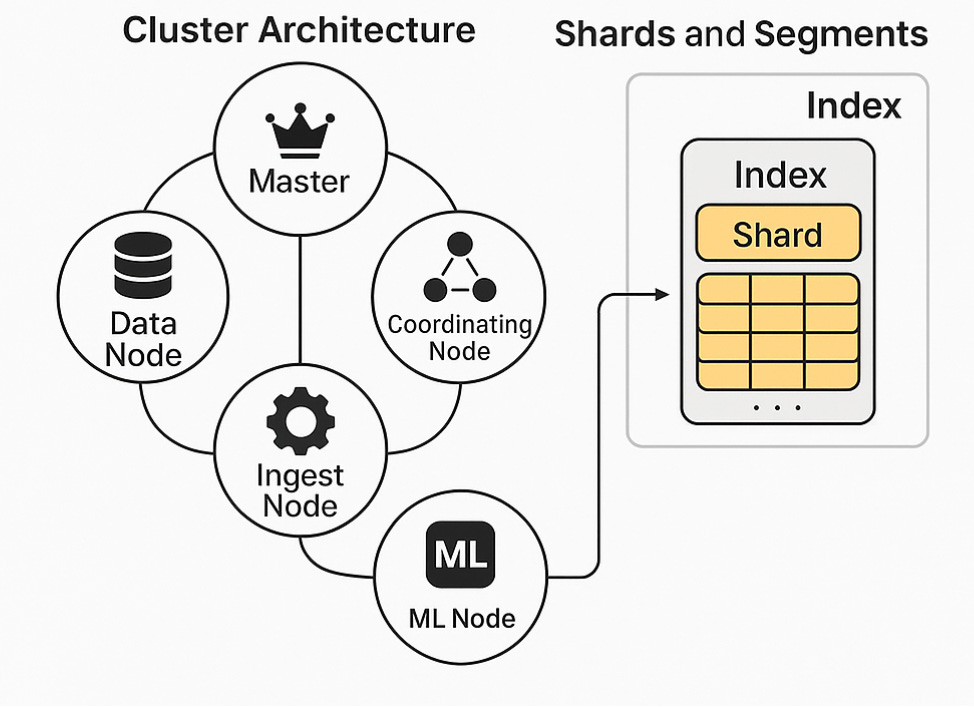
<Cluster Architecture - 노드 구성>
Master Node - 클러스터 관리 (노드 추가/삭제, 인덱스 생성 등)
Data Node - 실제 Document와 Index 저장
Coordinating Node - 쿼리 수신 및 분산 처리
Ingest Node - 데이터 전처리 파이프라인 수행
ML Node - 기계 학습 작업 전용
실제 검색 처리 흐름은 보통 Coordinating Node ↔ Data Node 간 상호작용으로 이루어지며,
대부분의 인터뷰에서 Data Node와 Coordinating Node 간의 흐름을 중심으로 묻습니다.
Elasticsearch의 데이터 정합성과 제약
Elasticsearch는 전통적인 OLTP DB와 달리 ACID 트랜잭션이 제한적이며, 즉각적인 일관성보다는 "최종 수렴(Eventual Consistency)"을 지향합니다.
문서 색인 후 즉시 검색이 되지 않을 수 있고, 일정 refresh 주기 후에야 반영됩니다.
따라서 강한 정합성이 필수인 금융 시스템에는 적합하지 않으며,
검색이 중요한 서브시스템 용도로 많이 사용됩니다.
원본 데이터는 RDBMS/NoSQL에 저장 → Elasticsearch에 비동기 CDC 동기화하여 검색 기능 분리
또한, Elasticsearch는 자유 텍스트 질의, 복잡한 필터 및 집계에 뛰어나 데이터 분석에 활용되지만, 조인이나 다중 컬렉션 간 연산은 미흡합니다. SQL이 지원되는 BI툴과 비교하면, ES의 DSL은 전문성이 요구되나 Kibana 등의 도구를 통해 시각화하기도 합니다. 성능 관점에서 Elasticsearch는 인덱스 구축과 질의 최적화에 초점을 맞추어 대량 데이터를 빠르게 검색하므로, 로그/이벤트 모니터링이나 추천 검색 자동완성, 지도 데이터의 지오코딩 등 실시간 검색 시나리오에서 RDBMS보다 훨씬 뛰어난 응답성을 보입니다. 그러나 반대로 초당 수천 건의 갱신 트랜잭션이 일어나는 워크로드에는 맞지 않으며, 데이터 업데이트보다는 추가 및 조회 중심의 사용 사례에 적합합니다.
Index 구조 상세 - Shard와 Segment
1. Shards & Replicas
Index는 여러 Shard로 나뉘어 Data Node에 분산 저장
각 Shard는 내부적으로 Lucene Index로 구현됨
Replica는 Shard의 복제본으로, 검색 성능 향상과 장애 복구용
2. Segments & CRUD
Segment는 Immutable (불변)
Insert - 새 Segment에 추가
Update - 기존 문서 Soft Delete → 새 문서 삽입
Delete - 실제 삭제는 Merge 시점에 처리
이러한 설계는 다음과 같은 장점을 가집니다
높은 쓰기 성능 - 기존 데이터에 영향 없이 추가 가능
병렬 검색 최적화 - Segment 단위로 병렬 검색 가능
캐싱 용이성 - Immutable 구조 덕분에 캐시 유지가 쉬움
내부 검색 구조
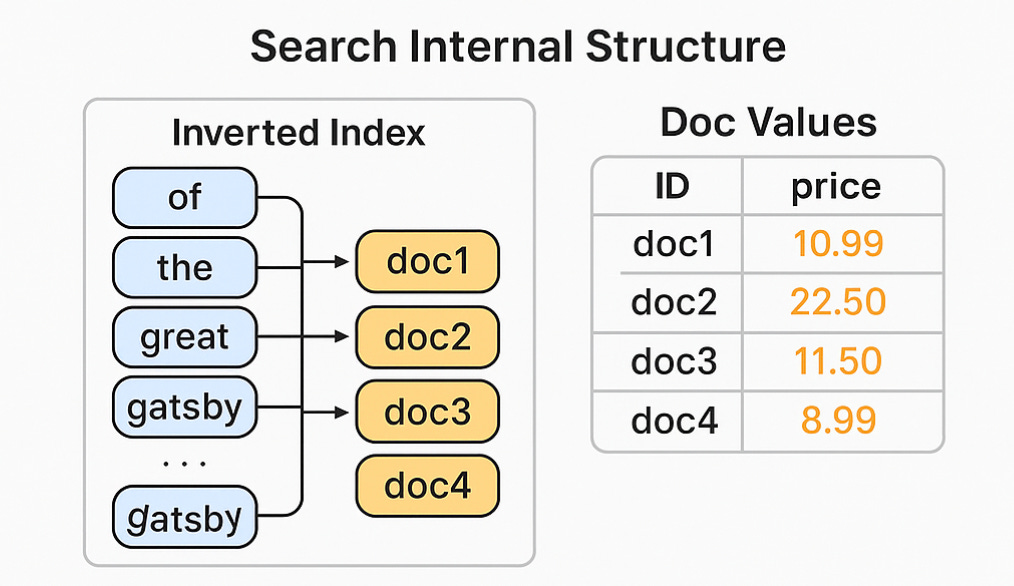
Inverted Index
단어 → 문서 ID 리스트 (e.g.
"great" → [doc1, doc5, doc8])O(n) 전수 검색이 아닌 O(1) 수준의 키워드 검색 가능
Doc Values
Columnar 저장 구조 (열 기반)
정렬, 필터, 집계 성능 향상
→price필드 기준 정렬 시 전체 JSON이 아닌 열만 탐색
검색 + 정렬 + 페이지네이션
{
"query": {
"bool": {
"must": [{ "match": { "title": "Great" } }],
"filter": [{ "range": { "price": { "lte": 15 } } }]
}
},
"sort": [{ "price": "asc" }]
}
Nested Field 정렬도 가능 (
reviews.rating기준 정렬 등)페이징 방식:
from + size,search_after,PIT (Point In Time)등
인터뷰 팁 - 적절한 사용 사례
검색 기반 서비스 (예: 게시물, 상품, 리뷰 등)
실시간 분석 (e.g. 로그 검색, 모니터링)
다중 필터/정렬/페이징이 필요한 목록 조회
<주의 사항!>
DB 대체 - 트랜잭션, 정합성 보장 부족 (Eventually Consistent)
쓰기 부하 주의 - Segment 구조상 Frequent Update에 비효율
동기화 필요 - CDC 등으로 원본 DB와 동기화 필요
Join 불가능 - Document 단위 검색에 최적화됨
결론적으로, Elasticsearch는 RDB가 못 하는 복잡한 검색을 빠르게 처리하기 위해 설계된 도구입니다.
인터뷰에서 Elasticsearch를 언급할 땐, 반드시 다음을 고려하세요
"왜 일반 DB로는 부족한가?"
"검색 시나리오에 최적화된 이유는 무엇인가?"
"데이터 일관성, 동기화 전략은 어떻게 설계할 것인가?"
지리정보 데이터베이스 (GeoSpatial DB)
왜 공간 데이터를 따로 다뤄야 할까?
우리가 사용하는 대부분의 서비스는 위치를 기반으로 움직입니다.
예를 들어,
"내 주변 카페 찾기"
"5km 반경 안에 있는 로보택시 호출"
캘리포니아주 샌프란시스코 전체에 광고 타겟팅"
이러한 질의는 단순한 숫자 비교가 아니라, 지도 위 좌표 간의 거리나 영역 포함 관계를 계산해야 하기 때문에 일반적인 RDBMS만으로는 효율적으로 처리하기 어렵습니다.
지리정보(GIS) 데이터베이스는 지도 좌표, 영역, 경로 등 공간 데이터를 효율적으로 저장하고 질의하기 위한 DB입니다. 가장 대표적인 구현은 PostgreSQL의 확장인 PostGIS로, 이 외에도 Oracle Spatial, MongoDB의 GeoJSON 지원, Google Earth Engine 등 다양한 형태가 있습니다. 공간 데이터는 점, 선, 폴리곤과 같은 기하 도형(Geometry)으로 표현되며, 일반 숫자/문자 데이터와 달리 2차원(혹은 3차원) 상의 관계를 다루기 때문에 특별한 인덱싱과 함수가 필요합니다.
Spatial Index (공간 인덱스)
공간 질의는 "범위 내 포함", "근접 거리", "교차 여부" 등을 계산합니다.
이런 연산을 빠르게 하기 위해 사용되는 것이 바로 공간 인덱스입니다.
가장 많이 쓰이는 구조는 아래와 같습니다.
R-Tree (범위 중심)
GiST (PostGIS의 인덱스 타입)
Quad-tree, Geohash, H3 (격자 기반)
질문 시나리오
"오스틴 반경 5km 안에 있는 모든 로보택시를 찾아라"
이걸 전체 데이터를 선형 탐색하면 너무 느리기 때문에,
PostGIS는 각 공간 데이터의 경계 박스(Bounding Box)를 인덱싱해
후보군만 빠르게 추려냅니다
→ 검색 속도 수백 배 향상하는 효과로 임팩트를 줄 수 있습니다.
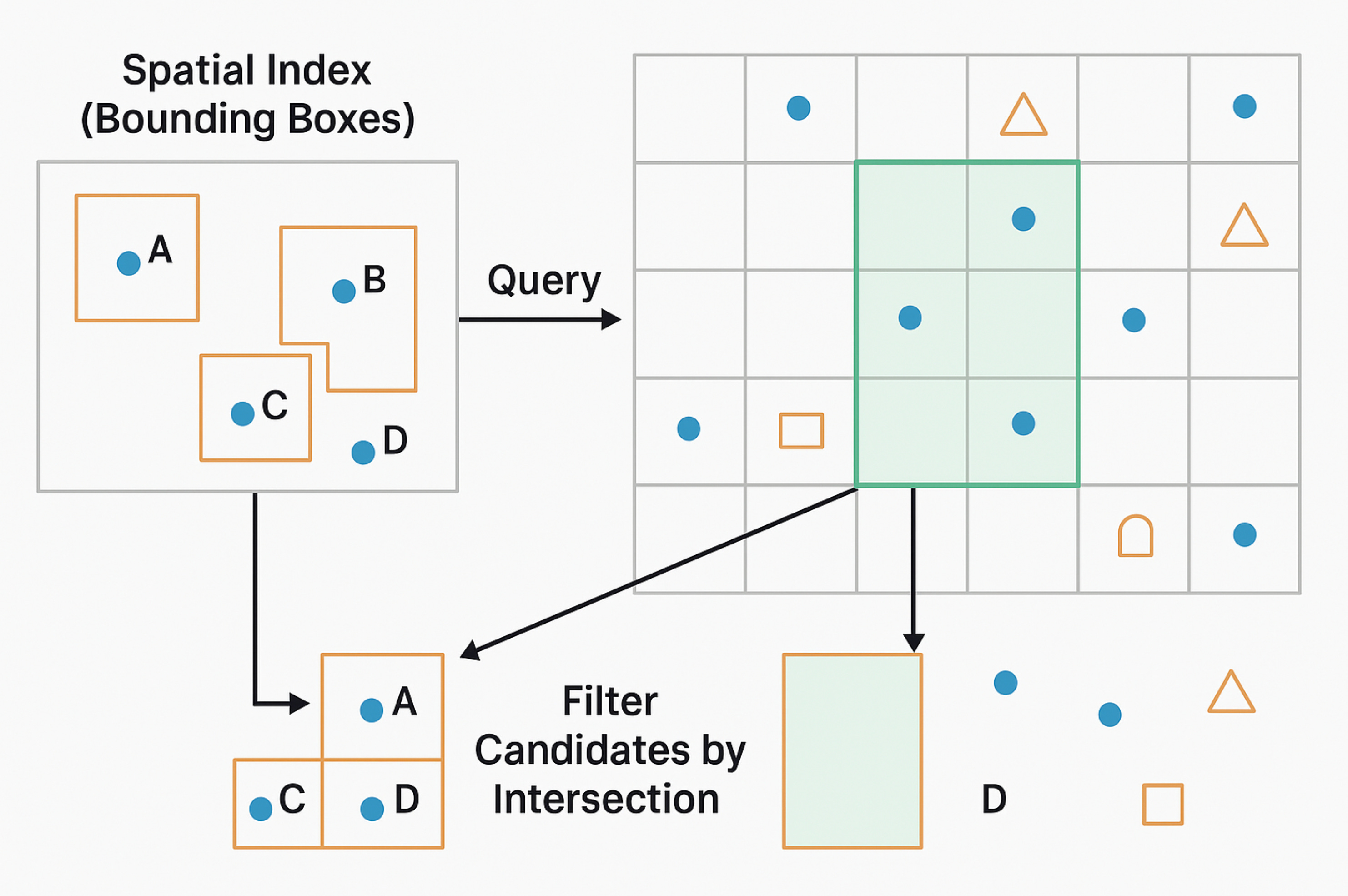
예를 들어 "이 경위도 사각형 범위 내의 모든 매장 찾기"나 "오스틴 반경 5km 내 로보택시 목록" 같은 질의는, 전체 데이터를 선형 검색하면 비효율적입니다. PostGIS는 GiST 인덱스로 각 지오메트리의 경계 박스를 색인화하여, 질의 시 후보군만 빠르게 추려냅니다. 이렇게 인덱스를 사용하면 수백만 건 중에서도 밀리초 수준으로 공간 연산이 가능해져, 실시간 위치 기반 서비스가 가능합니다. Uber 등의 플랫폼에서는 이러한 공간 인덱싱 기법을 커스텀하게 발전시켜 H3와 같은 전 지구 격자 시스템을 활용하기도 합니다.
지리 공간 함수
ST_Distance - 두 지점 간 거리 계산
ST_Within - 점이 다각형 안에 포함되는지
ST_Intersects - 선과 선, 선과 다각형이 교차하는지
ST_Contains - 영역 안에 대상이 포함되는지
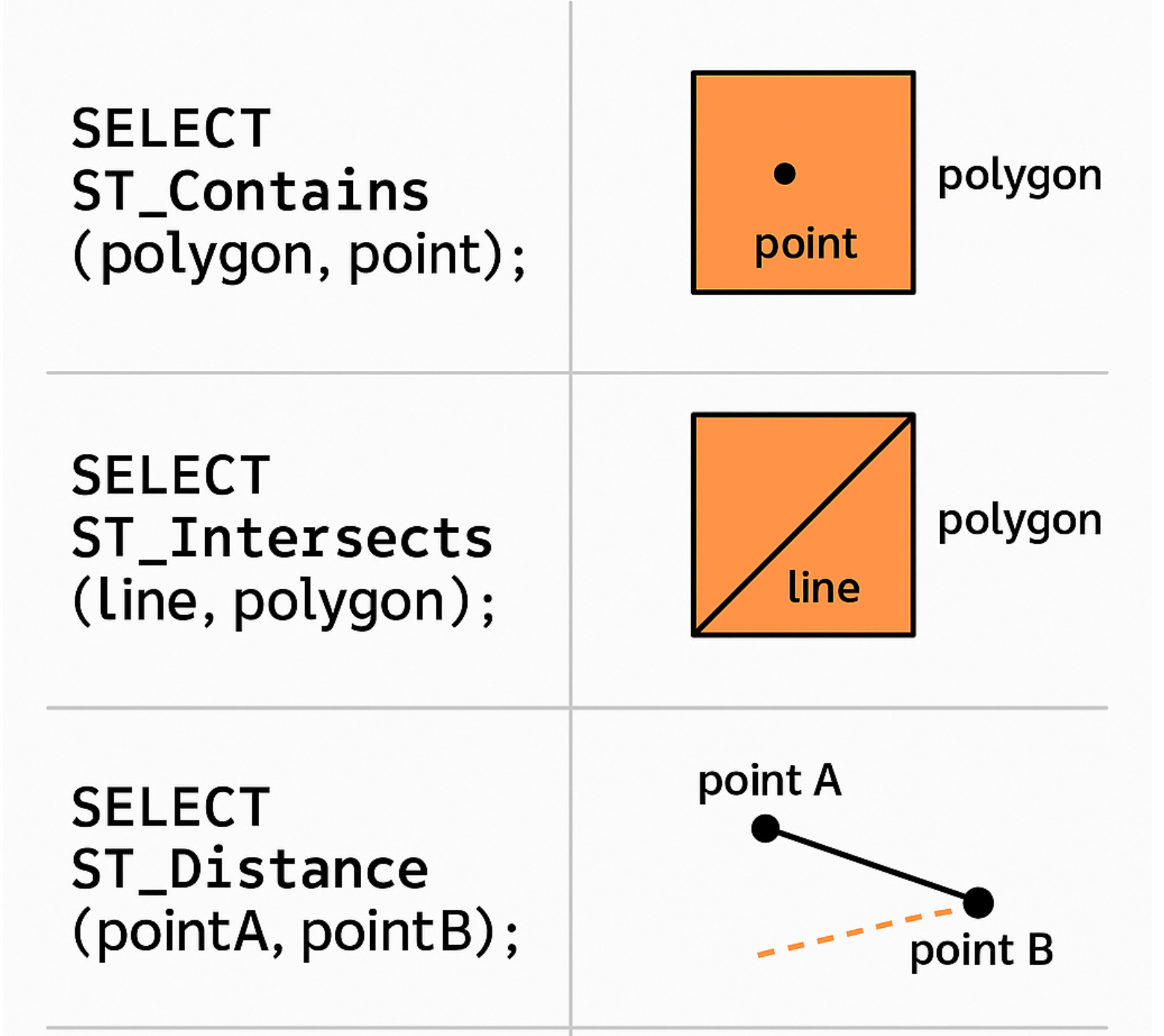
GIS DB는 거리 계산, 면적 계산, 위치 포함 여부(어떤 다각형 내에 점이 들어있는지, 선과 다각형 교차 여부 등)와 같은 유용한 함수를 제공합니다. PostGIS의 경우 ST_Distance, ST_Within, ST_Intersects 등의 함수를 통해 평면기하 계산을 데이터베이스 내에서 수행할 수 있습니다. 예를 들어 지역 검색(Geo-fencing) 기능은 ST_Contains(다각형, 점) 함수를 통해 구현되고, 최단경로 찾기는 그래프 DB와 결합하거나 도로망 데이터를 간선으로 모델링해 Dijkstra 함수를 실행하기도 합니다.
이런 연산은 데이터베이스 내부에서 바로 계산 가능하므로,
API 서버가 데이터를 가져와 직접 계산하는 것보다 훨씬 효율적입니다.
활용 사례
Uber
도시를 육각형 셀로 나누는 H3 격자 시스템 사용
→ 셀 단위로 수요를 집계하고, 인접 셀만 빠르게 탐색
→ 수요-공급 불균형 감지, 동적 요금제(Surge Pricing), 운전자 배치 최적화
위치 기반 서비스(LBS), 내비게이션, 물류 경로 최적화, GIS 분석 등이 공간 DB의 주요 사용처입니다. 예를 들어 우버(Uber)는 자체 개발한 H3 공간 격자를 통해 도시를 헥사곤 그리드로 나누고 운행 데이터를 그 격자 단위로 집계하여 수요/공급 불균형을 파악하고 동적 가격(Surge Pricing)을 계산합니다. 이처럼 전세계 지리를 셀(cell) 단위로 분할하면, 인접 셀만 탐색함으로써 특정 위치 주변의 정보를 빠르게 얻고, 메쉬 기반의 효율적인 공간 연산을 할 수 있습니다. Uber의 H3는 이러한 목적에 최적화된 예로서, 승객-운전자 매칭이나 차량 배치 최적화에 활용되고 있습니다.
요약하면, 지리정보 DB는 공간적인 질의 (“~와 가까운”, “~안에 있는”)를 빠르게 처리하는 특수 목적 시스템입니다. 면접에서 “우버, 테슬라와 같은 로보택시, 일반 차량 호출 시스템 설계”를 논한다면, 단순히 RDB나 Key-Value만 언급하기보다 이러한 지리 공간 인덱스나 H3 같은 격자 시스템을 언급하면 깊이 있는 답변이 될 것입니다.
인터뷰 팁
단순히 RDB에 좌표 필드 하나 넣는 걸로는 부족합니다.
“내 주변의 OO 찾기”, “지역 안에 있는 xyz 보여주기” 같은 질의가 나올 경우,
반드시 공간 인덱스, PostGIS 또는 H3 같은 전용 구조 도입을 제안해야 합니다.Uber, 도어대시 등 위치 기반 시스템 디자인이 주제로 나오면,
“위치 기반 매칭은 공간 인덱싱 기반으로 처리”한다는 점을 꼭 언급하세요.
다음에서 이어집니다.