
Consistent Hashing 에 대해서
Consistent Hashing (일관 해싱) 은 어떤 문제를 해결하고, 어떻게 작동하며, 인터뷰에서 어떻게 활용할 수 있을까요?

서론
시스템 디자인 인터뷰를 준비하면서 "Consistent Hashing(일관 해싱)" 이라는 개념을 접해본 적이 있을 것입니다.
이는 분산 시스템의 기초 알고리즘으로, 데이터를 여러 서버 클러스터에 분산하는 데 사용됩니다.
온라인에는 수천 개의 설명 자료가 있지만, 대부분 지나치게 학술적이고 직관적이지 않습니다. 이 가이드는 인터뷰 준비를 위해 Consistent Hashing의 문제 정의, 동작 방식, 인터뷰 활용법을 초점 있게 다룹니다.
시나리오를 통한 이해
기본 시나리오
티켓마스터(TicketMaster) 같은 티켓팅 시스템을 설계한다고 가정해봅시다.
초기에는 하나의 데이터베이스에 모든 이벤트 데이터를 저장
클라이언트는 단일 DB에서 이벤트 정보를 요청
Client → Server → Database
처음에는 잘 작동합니다.
하지만 성공이 문제를 가져옵니다. 이벤트가 많아지면서 단일 DB가 감당하지 못합니다.
따라서 데이터를 여러 DB로 나누어 저장해야 하는데, 이를 샤딩(Sharding) 이라고 합니다. 하지만 문제가 여기서 시작이 됩니다.
문제 - 어떤 이벤트를 어느 DB에 저장할까?
첫 시도에는 단순 모듈로 해싱 (Modulo Hashing)
가장 직관적인 방법은 모듈로 연산(%) 을 사용하는 것을 고려할 수 있습니다.
이벤트 ID → 해시 함수 적용 → 숫자로 변환
그 숫자를 DB 개수로 나눈 나머지를 사용
결과값에 해당하는 DB에 이벤트를 저장
database_id = hash(event_id) % number_of_databases예시 (DB가 3개일 때)
이벤트 #1234 → hash(1234) % 3 = 1 → DB1
이벤트 #5678 → hash(5678) % 3 = 0 → DB0
이벤트 #9012 → hash(9012) % 3 = 2 → DB2
이 방식은 처음에는 잘 작동합니다. 하지만, 노드가 추가되거나 삭제가 일어나면 문제가 발생합니다.
문제 1 - 노드 추가 시 (Adding a Node)
기존의 DB를 3개에서 4개로 늘리고 싶습니다.
database_id = hash(event_id) % 4모듈로 방안을 통해서 늘려보았지만, 이제 문제가 발생합니다.
단지 DB 하나를 추가했을 뿐인데, 기존 대부분의 데이터가 다른 DB로 재분배되어야 합니다. 왜냐하면 기존의 데이터들이 모두 다시 계산되어 재분배가 일어나게 되기 때문입니다.
기존의 이벤트 매핑이 깨지면서 데이터 이동이 폭발적으로 발생 → DB 부하 증가, 서비스 장애
이벤트 #1234 → 원래는 DB1 → 이제는 DB0
문제2 - 노드 제거 시 (Removing a Node)
그러던 중, 만약 DB 중 하나가 장애로 내려가면?
3개에서 2개로 줄어들면서 hash(event_id) % 2 를 다시 계산해야 합니다.
→ 결국 동일한 대규모 재분배 문제가 다시 발생합니다.
위와 같은 문제점을 해결하기 위해서 Consistent Hashing 을 사용하게 됩니다.
Consistent Hashing
Consistent Hashing은 분산 시스템에서 노드 추가/제거 시 재분배를 최소화하는 기법입니다.
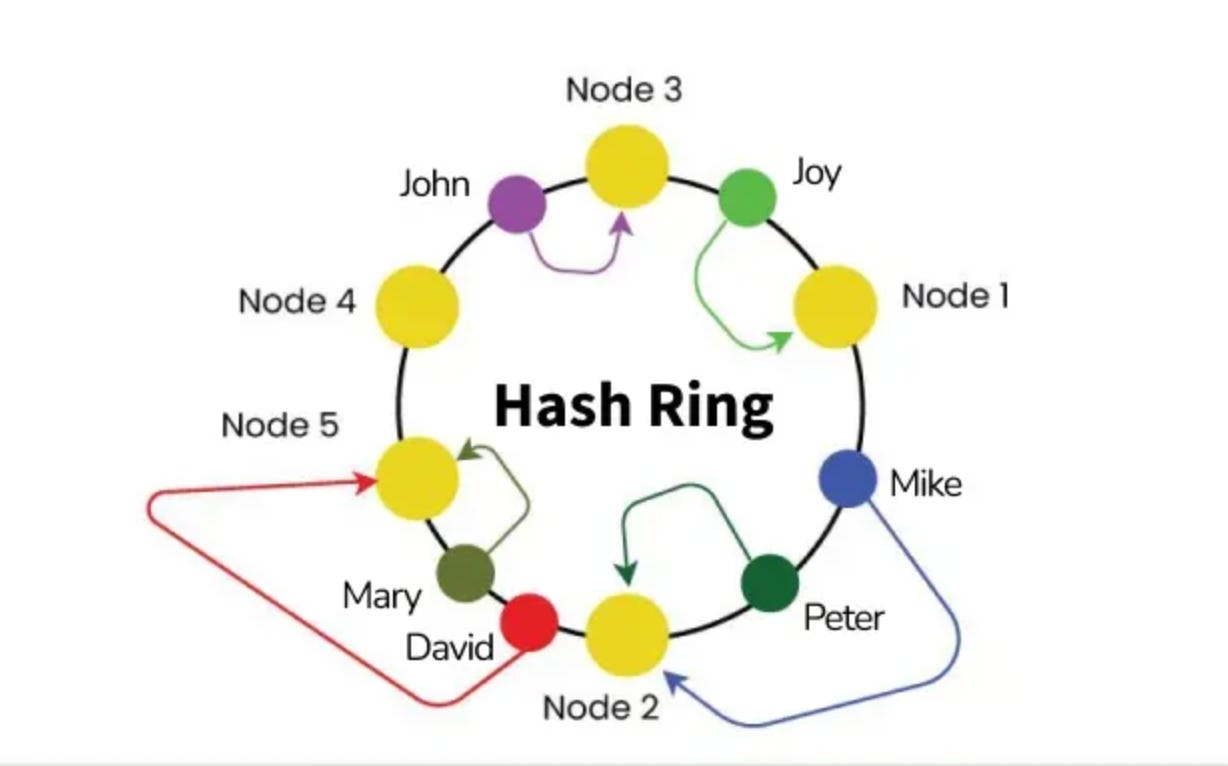
데이터와 서버(DB)를 원형 공간(Hash Ring) 에 배치
각 이벤트를 해시하여 원형 상의 위치를 찾고, 시계 방향으로 가장 가까운 서버에 매핑
동작 방식
해시 공간을 원형으로 만듦 (예: 0 ~ 2³²-1)
서버(DB)를 해시 링의 특정 지점에 배치 (예: DB1=0, DB2=25, DB3=50, DB4=75)
이벤트 해시 값을 링 위에 놓고, 시계 방향으로 이동해 가장 가까운 서버에 저장
이미지 출처: https://www.geeksforgeeks.org/system-design/consistent-hashing/
그래서 만약 노드가 추가된다면?
예: DB5를 위치 90에 추가
75~90 구간의 데이터만 DB1에서 DB5로 이동
전체 데이터의 약 15%만 이동 → 나머지는 그대로 유지
노드가 제거되는 경우에는?
예시) DB2(25 위치) 장애가 일어났습니다.
DB2에 매핑된 이벤트만 DB3(50 위치)로 이동 그리고 나머지는 그대로 유지
가상 노드 (Virtual Nodes)
특정 노드 장애 시, 이웃 노드(DB3)가 과부하가 될 수 있음.
해결책으로 가상 노드(Virtual Nodes) 를 사용합니다.
가상 노드(vnode) 로 편향 완화 & 부하 분산.
각 DB를 링 위에 하나가 아닌 여러 지점에 배치
예: DB1 → "DB1-vn1", "DB1-vn2", "DB1-vn3"
이렇게 하면, 특정 노드 장애 시 → 여러 서버로 고르게 분산
실제 사례
Consistent Hashing은 DB뿐 아니라 다양한 시스템에서 사용됩니다.
Apache Cassandra
데이터 분산 저장
Amazon DynamoDB
내부적으로 Consistent Hashing 사용
CDN (Content Delivery Network)
어떤 엣지 서버에 캐싱할지 결정
인터뷰에서의 활용
분산 시스템(DynamoDB, Cassandra 등)은 이미 내부적으로 Consistent Hashing을 사용합니다. 따라서, 인터뷰에서 DB 선택 시 → "DynamoDB는 내부적으로 Consistent Hashing을 사용하므로 확장이 가능하다" 정도 언급하면 충분할 때가 많습니다.
하지만 인프라 중심 인터뷰에서는 직접 설명할 준비가 필요합니다.
왜 Consistent Hashing이 단순 모듈로보다 좋은가?
가상 노드(Virtual Nodes)가 왜 중요한가?
노드 추가/제거 시 어떻게 안정적으로 동작하는가?
핫스팟(Hot Spot)과 재밸런싱(Rebalancing) 전략은 어떻게 하는가?
결론
Consistent Hashing은 "서버 개수가 변할 때 데이터 재분배를 최소화한다"라는 단순하지만 강력한 아이디어입니다.
구현은 복잡할 수 있지만, 핵심 원리는 직관적입니다
원형으로 배치하고 시계 방향으로 이동
DynamoDB, Cassandra 등 우리가 매일 쓰는 분산 시스템에서 이미 활용 중
인터뷰에서 대부분은 직접 구현할 필요 없습니다.
"이 DB는 Consistent Hashing을 내부적으로 사용한다" → 충분
하지만 인프라 설계 문제(분산 DB, 캐시, 메시지 브로커 설계)에서는 깊이 있는 설명을 준비해야 합니다.